Der Sicherheitsfaktor ist natürlich nicht wegzudenken. Deshalb die Daten ja auf dem NAS. Und es darf nur der darauf zugreifen der auch das Recht hat.
Da aber HA nun mal Zentrale Aufgaben übernimmt und es sich smart in den Alltag integriert so wäre eine Abfrage über das HA Dashboard doch nicht so abwegig.
Also ich schau mir die Sache mal genauer an und schaue dann was alles machbar ist. Es hört sich aber auf jeden Fall sehr vielversprechend an.
Keine Ahnung, ob Du meine Posts liest, aber es gibt auch eine API, https://docs.paperless-ngx.com/api/
Damit könntest Du da auch aus HA kleine Abfragen starten, wer noch mehr machen möchte, kann sich paperless-ai installieren
Auch dazu habe ich schon Links gepostet.
Natürlich habe ich auch deine Posts dazu gelesen. Deshalb finde ich es ja gerade interessant. Und würde wieder wechseln. Auch wenn es für mich bedeutet wieder mit allen Dokumenten umzuziehen was ja auch jede Menge Arbeit bedeutet. Da diese ja nun mal in einer Datenbank liegen. Doch man lernt ja auch jedes mal dazu. Ich bin schon dabei die Basis zu installieren und schau mir die Sache mal genauer an. Nur zwischendurch muss ich was arbeiten gehen. Die Kohle muss ja ins Haus kommen.
Eine Frage habe ich aber an dich. Mein Scanner ist so eingestellt das er in einem Ordner die Dokumente ablegt. Alles soweit so gut. Was passiert bei Paperless wenn es sich beim scannen um eine Vielseitiges Dokument handelt. Sagen wir mal 10 Seiten. Eine Datei wird ja schon bei der ersten Seite angelegt. Die Datei ist aber noch nicht fertig da weitere Seiten folgen. Bei Paperoffice ist häufig der Fall das diese Datei rausgeworfen wurde und somit nicht bearbeitet. Da Paperoffice jedoch erst arbeitet wenn der Client auf dem PC offen ist habe ich immer gescannt wenn es zu war. Jedoch hat er sich dann die Datei nicht mehr automatisch genommen. Das ging nur wenn der Client offen ist. Das aber nur bei normalen 1-4 Seiten scanns.
Das ist schon mal ein Punkt der mir bei PaperOffice nicht gefällt. Du musst immer aufpassen was du gerade tust. Das funktionierte bei EcoDMS besser. Doch hier musste halt immer der PC an sein das du irgendwas machen kannst. Deshalb wollte ich was für die NAS.
So, hab jetzt Tika und Gotenberg am laufen, da ich halt nicht wirklich Ahnung habe, hab ich es so gemacht, es läuft, geht vermutlich aber viel leichter, aber vielleicht hilft es dem ein oder anderen.
Paperless läuft unter Proxmox und wurde mittels Community Script installiert.
Schritt 1:
Tika mit diesem Script installiert:
Schritt 2:
Docker LXC installieren mit diesem Script:
Schritt 3:
Folgenden Befehl in der Console vom Docker LXC eingeben:
docker pull gotenberg/gotenberg
Schritt 4:
Paperless.conf mit folgendem ergänzen:
# Tika settings
PAPERLESS_TIKA_ENABLED=true
PAPERLESS_TIKA_ENDPOINT=http://EURE_IP:9998
PAPERLESS_TIKA_GOTENBERG_ENDPOINT=http://EURE_IP:3000
Natürlich müsst ihr die IP Adressen so anpassen, das sie zu euren LXC Containern passen.
Damit Gotenberg im Docker automatisch startet, sollte der Container mal neustarten, habe ich folgenden Befehl in der Console des Docker LXC eingegeben:
docker run --restart always -p 3000:3000 gotenberg/gotenberg:8
das hängt ein wenig davon ab, ich muss sagen, dass ich darauf noch nicht geachtet habe, ich habe maximal zwei bis vier Seiten, werde ich aber morgen mal ein Test machen.
Ich glaube, bei mir wird es nicht mit dem Präfix .pdf geschrieben, erst wenn die letzte Seite fertig ist, wird es als document.pdf geschrieben, ist so ähnlich wie beim Download einer großen Datei, da steht auch immer download.zip.part erst, wenn der Download abgeschlossen ist, wird daraus download.zip.
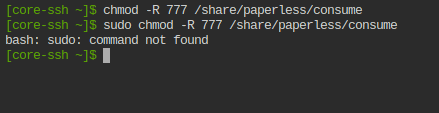
In HA bin ich als Admin angemeldet. Sudo scheint es da jedoch nicht zu geben.
Hab es auch versucht, auf meinem Laptop mit Kubuntu, da funktioniert es. Aber anscheinend speichert es die Berechtigung nicht auf dem NAS. Bin aber leider kein ITler, daher bin ich da etwas überfragt.
Ich habe paperless mit tika und gotenberg in einer VM unter proxmox laufen.
Mein consume Ordner und die Datenhalde liegen nicht in der VM, sondern auf meinem NAS. Per Netzwerk gemounted und dann per Link aus der VM umgebogen. War ein wenig Fummelei.
Die VM wird zweimal täglich automatisch per snapshot gesichert, auf dem NAS habe ich ein anderes Konzept und sichere von dort seltener auf ein zweites NAS.
Als Scanner kann ich einen Epson workforce 580w als Einzugsscanner empfehlen. Ist netzwerkfähig, und scannt ein- oder beidseitig bei mir direkt aufs NAS in den consume Ordner. Schneller geht’s nicht.
Der 780w wurde mal in der c’t als gut befunden, war mir aber dafür zu teuer. Der kleinere ist immer noch schnell genug und zieht genug Seiten automatisch ein, um auch mal größere Dokumente zu sichern. Probleme mit mehreren Seiten habe ich hier noch nie gehabt.
Guten Morgen, das mit der Trennseite kenne ich. Doch ich meinte solche Beläge die aus 10 Seiten bestehen. Stromabrechnung fällt mir da gerade ein. Natürlich mittlerweile online doch es wäre ein Beispiel.
Doch instllieren auf meiner NAS kann ich vergessen. Kommt immer eine Fehlermeldung beim Container anlegen.
failed to create application "paperless-ngx". error message: no matching manifest for linux/arm/v7 in the manifest list entries
Und wenn ich das richtig gegoogelt habe kommt er mit meiner NAS nicht klar. Habe die QNAP TS-231P
In wie weit du die Container Station auf der QNAP updaten kannst usw weiß ich nicht. Hab noch nie QNAP verwendet. Aber generell sollte ja Docker oder LXC drauf laufen.
Danke Dir für deinen Hinweis. Dann probiere ich das mal mit dem Docker.
Man lernt nie aus… kommen immer wieder neue Dinge hinzu. Keine Ahnung was Docker ist, doch wenn ich fertig bin weiß ich darüber mehr. Bin mal gespannt was da wieder auf mich zukommt. Die nächsten Abende sind schon mal nicht mit langeweile gespickt
ich denke, paperless-ngx gibt es für die ARM Architektur nicht, müsste ich aber auch erst einmal nachschauen.
Das war auch nicht auf das 10 Seitenproblem gemeint, sondern allgemein
Wie es sich verhält, wenn man direkt 100 Seiten in den Consum Ordner scannt, muss ich mal testen.
ich versuche das gerade auch so aufzusetzen, habe aber Probleme mit den Berechtigungen.
Mein consume und export Ordner liegen auf meinem NAS. Dies habe ich auch soweit über Proxmox an den Container durchreichen können, so dass ich die SMB Freigabe mounten und auch beschreiben kann.
Mein User ist in diesen Gruppen: uid=1000(tobias) gid=990(docker) groups=990(docker),100(users),1000(tobias),10000(lxc_shares)
Mein SMB Share hat diese Berechtigung:
drwxr-xr-x 3 root root 4096 Mar 19 06:30 ..
-rwxrwx--- 1 root lxc_shares 8196 Mar 19 11:17 .DS_Store
drwxrwx--- 2 root lxc_shares 0 Mar 19 11:03 consume
drwxrwx--- 2 root lxc_shares 0 Mar 19 07:24 export
Im docker-compose.env file habe ich für die UID und GID folgendes angegeben:
USERMAP_UID=1000
USERMAP_GID=10000
In der docker-compose.yaml habe ich noch für den webserver die Zeile user: "1000:10000" ergänzt.
Doch leider meldet der Container beim Start immer:
Paperless-ngx docker container starting...
Mapping UID and GID for paperless:paperless to 1000:10000
usermod: no changes
groupmod: Permission denied.
groupmod: cannot lock /etc/group; try again later.
Hast Du zufällig eine Idee, was hier das Problem ist?
Bei den Volumes hatte ich auch Probleme mit den Berechtigungen. Das konnte ich lösen, indem ich auf dem Server mein Home-Verzeichnis angelegt habe. Da Paperless bei mir auf Proxmox in einem unprivilegierten Container läuft, benutze ich Syncthing, um die Scans in den Consume-Ordner zu synchronisieren. Das funktioniert bei mir ganz gut. Außerdem ist die Erweiterung von Gothenburg enthalten. Damit können auch Word und Co. in Paperless indexiert werden.
Ich hatte mich an diese Anleitung gehalten und dort wurde die neue Gruppe mit der ID 10000 angelegt.
Jetzt habe ich im docker-compose.env file USERMAP_GID auskommentiert, wie hier erwähnt. So scheint es zu laufen.
Gothenburg läuft bei mir auch. Das muss ich aber noch testen.
Alles sehr komplex. Habe jetzt auch einiges dazu gelesen und unter dem Stichwort rootless container findet man einige, die Probleme haben Paperless ans laufen zu bekommen.
In dem Beitrag zur GID läuft Paperless auf Kubernetis, das stimmt.
Aber das war der einige Tipp, mit dem ich etwas anfangen konnte. Sonst wurde immer nur auf das docker user mirroring verwiesen:
Das habe ich allerdings ehrlicher Weise nicht verstanden
Bei mir läuft alles unter Docker in einem Ubuntu LXC Container auf Proxmox.
Hier sind meine Compose-Files:
docker-compose.yaml
services:
broker:
image: docker.io/library/redis:7
restart: unless-stopped
volumes:
- redisdata:/data
db:
image: docker.io/library/postgres:16
restart: unless-stopped
volumes:
- pgdata:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: paperless
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
user: "1000:10000"
restart: unless-stopped
depends_on:
- db
- broker
- gotenberg
- tika
ports:
- "8050:8000"
volumes:
- /mnt/paperless/data:/usr/src/paperless/data
- /mnt/paperless/media:/usr/src/paperless/media
- /mnt/paperless/export:/usr/src/paperless/export
- /mnt/paperless/consume:/usr/src/paperless/consume
env_file: docker-compose.env
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_TIKA_ENABLED: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://gotenberg:3000
PAPERLESS_TIKA_ENDPOINT: http://tika:9998
gotenberg:
image: docker.io/gotenberg/gotenberg:8.7
restart: unless-stopped
# The gotenberg chromium route is used to convert .eml files. We do not
# want to allow external content like tracking pixels or even javascript.
command:
- "gotenberg"
- "--chromium-disable-javascript=true"
- "--chromium-allow-list=file:///tmp/.*"
tika:
image: docker.io/apache/tika:latest
restart: unless-stopped
volumes:
pgdata:
redisdata:
docker-compose.env
# The UID and GID of the user used to run paperless in the container. Set this
# to your UID and GID on the host so that you have write access to the
# consumption directory.
USERMAP_UID=1000
#USERMAP_GID=10000
# See the documentation linked above for all options. A few commonly adjusted settings
# are provided below.
# This is required if you will be exposing Paperless-ngx on a public domain
# (if doing so please consider security measures such as reverse proxy)
#PAPERLESS_URL=https://paperless.example.com
# Adjust this key if you plan to make paperless available publicly. It should
# be a very long sequence of random characters. You don't need to remember it.
#PAPERLESS_SECRET_KEY=change-me
# Use this variable to set a timezone for the Paperless Docker containers. Defaults to UTC.
PAPERLESS_TIME_ZONE=Europe/Berlin
# The default language to use for OCR. Set this to the language most of your
# documents are written in.
PAPERLESS_OCR_LANGUAGE=deu
# Additional languages to install for text recognition, separated by a whitespace.
# Note that this is different from PAPERLESS_OCR_LANGUAGE (default=eng), which defines
# the language used for OCR.
# The container installs English, German, Italian, Spanish and French by default.
# See https://packages.debian.org/search?keywords=tesseract-ocr-&searchon=names&suite=buster
# for available languages.
#PAPERLESS_OCR_LANGUAGES=tur ces
PAPERLESS_OCR_MODE=force
PAPERLESS_CONSUMER_POLLING=60
Wie gesagt, so läuft es erstmal. Hoffentlich bleibt das auch so während meiner Tests.
Schwierig wird es, sich auf einige Standards wie Tags, Dokumententypen und Dateinamen/ -pfade festzulegen.
Hallo zusammen
Danke @simon42 für das super Video. Ich konnte alles entsprechend einrichten.
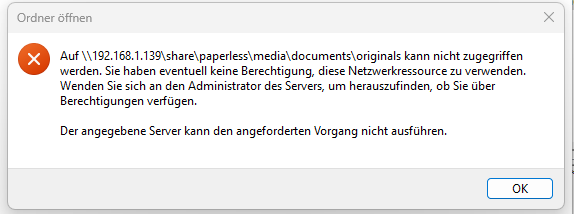
Zu meinem Setup. Ich habe meinen Homeassistant über einen Intel Nuc. Also direkt installiert. Nicht über Proxmox oder so. Nun habe ich noch das Addon Samba Share installiert, so das ich auf die Ordner von Homeassistant komme vom Windows PC. Klappt soweit auch, nur leider bei diesen 2 wichtigen Ordnern
\192.168.1.139\share\paperless\media\documents\archive
\192.168.1.139\share\paperless\media\documents\originals komme ich nicht rein.
Hat einer eine Idee wie ich diese Ordner freischalten kann? Wie gesagt, auf andere Ordner komme ich ohne Probleme. Zb. Dieser Ordner \192.168.1.139\share\paperless\media\documents\thumbnails
Ich versuche - wie in der FAQ beschrieben - den Ordner paperless auf einen freigegeben Ordner auf meiner Synology zu legen, denn der Ordner wird mir langsam zu groß. Ich kann das share zwar mounten, aber das paperless-addon startet dann nicht mehr. Dem Protokoll entnehme ich, dass der Besitzer auf dem gemounteten share nicht stimmt, bzw. die Dokumente vom add-on nicht übernommen werden können, da es auf den entsprechenden Besitzer auf der Synology nicht gibt.
Hat das jemand geschafft, und war ist da der Trick?