Zu deinen drei Punkten — die sind tatsächlich alle bereits Teil meiner Architektur oder aktiv in Arbeit:
1. Vorjahresdaten zum Anlernen
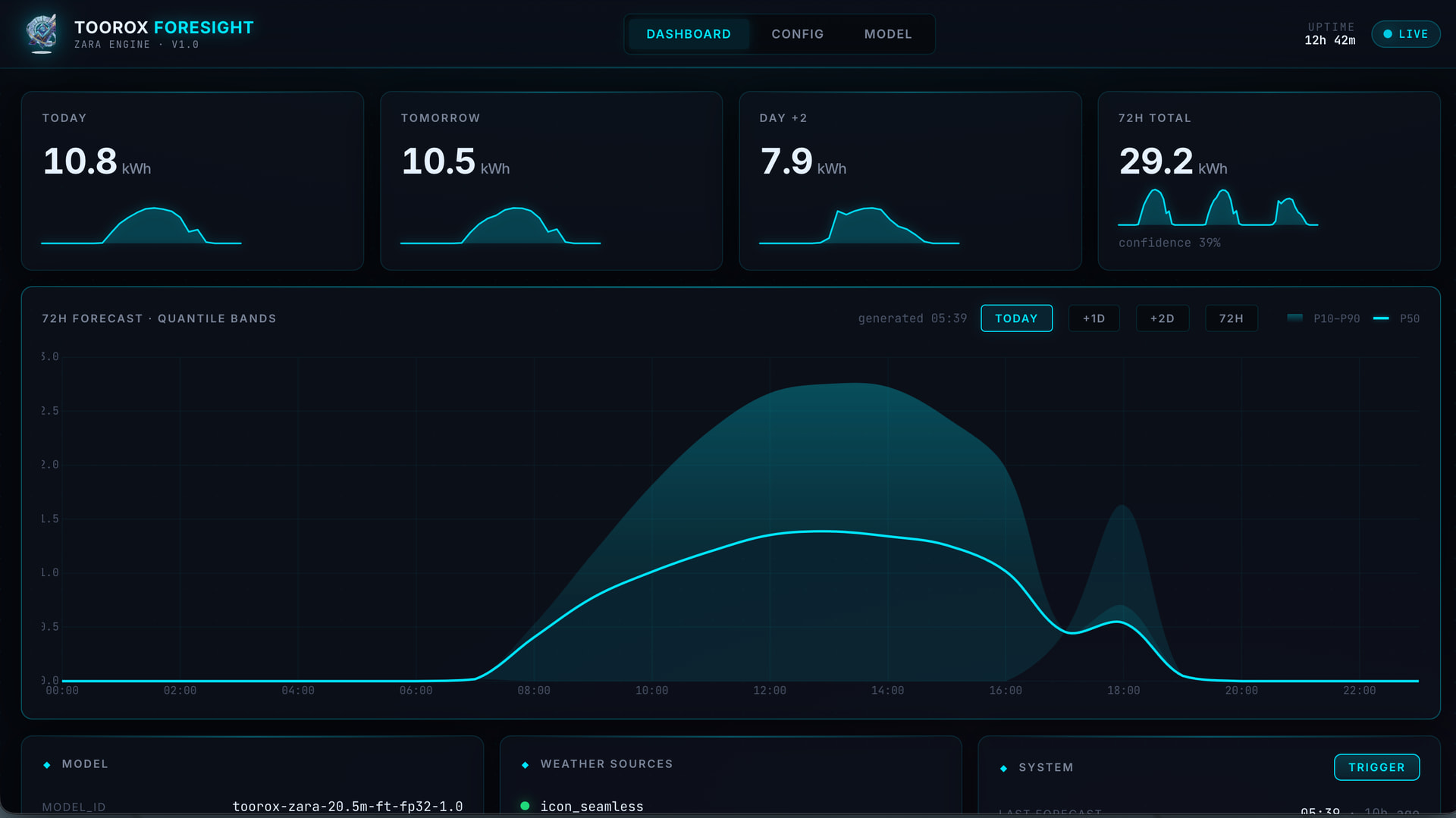
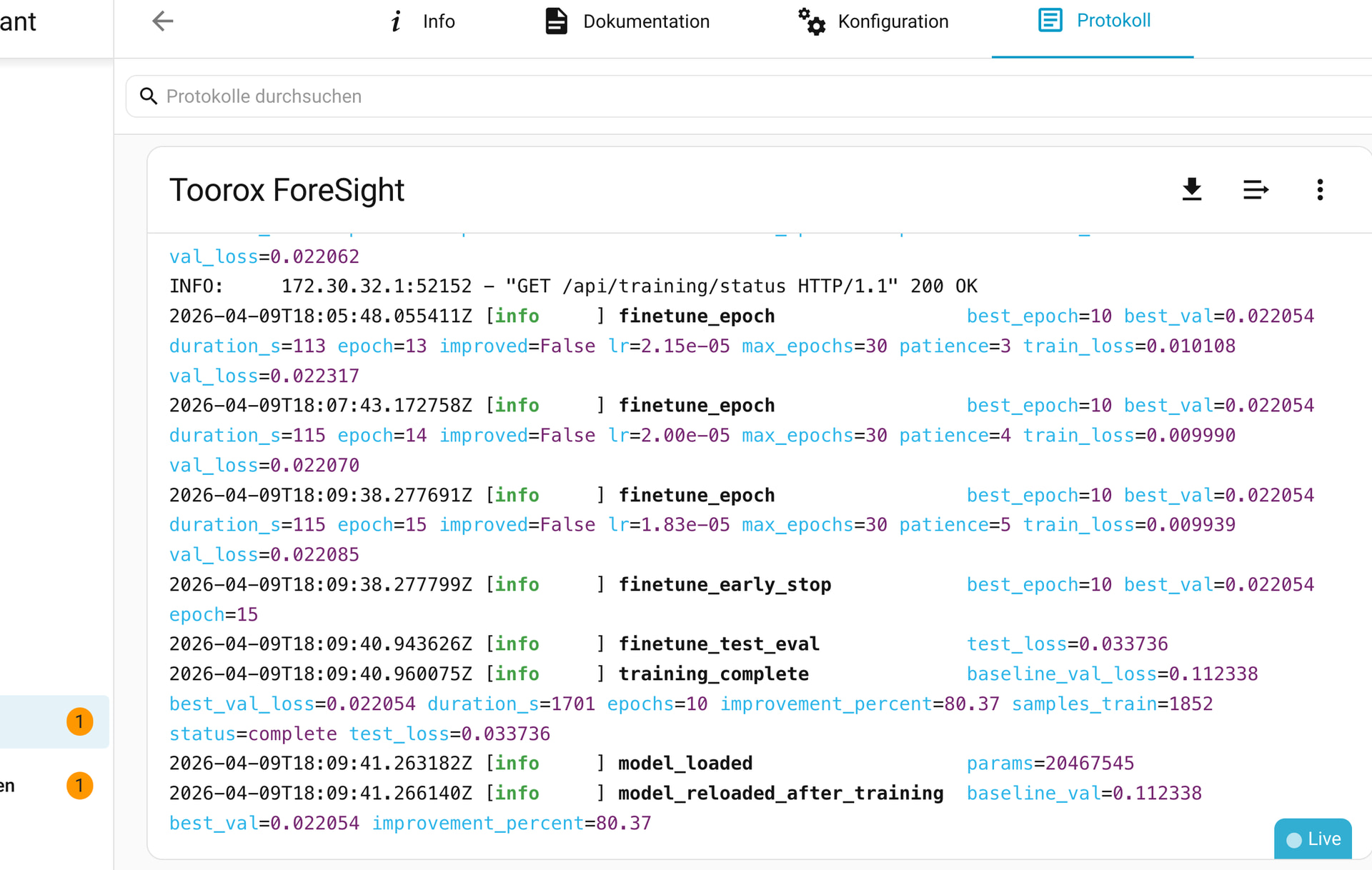
Genau so funktioniert es. ForeSight wird mit einem vortrainierten Modell ausgeliefert, das auf synthetischen Solardaten von über 500 europäischen Standorten (18 Jahre pro Standort) gelernt hat. Beim ersten Start auf deiner Hardware macht es automatisch ein Fine-Tuning auf deine echten Produktionsdaten — je mehr Historie vorhanden ist, desto besser. 10+ Tage reichen für den Start, aber mehrere Monate machen das Modell natürlich deutlich robuster. Wenn du also Daten hast die du einspeisen kannst: perfekt, genau dafür ist der automatische Import-Mechanismus gedacht → SFML DATENBANK MUSS 100% sauber sein, sonst zerschießt es die Trainingsdaten, kein Sensor-Trouble, keine Fehlkonfiguration,..
2. Einzelne Panelgruppen separat lernen
Aktuell unterstützt das Modell bis zu 4 Panelgruppen mit individueller Ausrichtung, Neigung und Leistung. Das Pre-Training deckt bewusst verschiedene Konfigurationen ab (Süd, Ost, West, Flachdach), und das Fine-Tuning auf deiner Anlage lernt dann die spezifischen Unterschiede pro Gruppe — unterschiedliche Module, Verschattung, Inverter-Verhalten etc. Das Modell gibt pro Gruppe eine eigene Prognose aus, nicht nur einen skalierten Gesamtwert.-> exact so wie SFML
3. Leistungsstarkes Subsystem fürs Training
Sehr guter Gedanke, und genau das habe ich umgesetzt. Das Pre-Training (das rechenintensive Grundlernen auf den 500+ Standorte) läuft auf einer dedizierten AMD-Workstation mit 2 GPU. Ihr bekommt das fertig trainierte Modell und müsst nur noch das leichte Fine-Tuning auf seiner eigenen Hardware machen — das dauert auf einem normalen x86-System etwa 10 Minuten, kein GPU nötig. Ein Raspberry Pi 5 schafft das ebenfalls, dauert dann etwas länger. Die schwere Arbeit passiert also bereits bei mir (das Training).
Dein Szenario “RPI als Hauptsystem + AMD im Haus fürs Anlernen” ist ein interessanter Ansatz. Aktuell ist das nicht nötig weil das Fine-Tuning bewusst so leicht gehalten ist dass es auf dem Hauptsystem mitläuft — aber wenn jemand sehr viele Daten oder sehr häufiges Re-Training will, ist die Architektur dafür offen (HTTP-API, Checkpoint-Dateien sind portabel).
Kurz zusammengefasst: du denkst genau in die richtige Richtung. Das System ist darauf ausgelegt, lokal und privat zu laufen, aus echten Daten zu lernen, und auch auf moderater Hardware performant zu sein.
Bei Fragen zur ioBroker-Integration oder zum Docker-Setup: gerne melden.
Zara