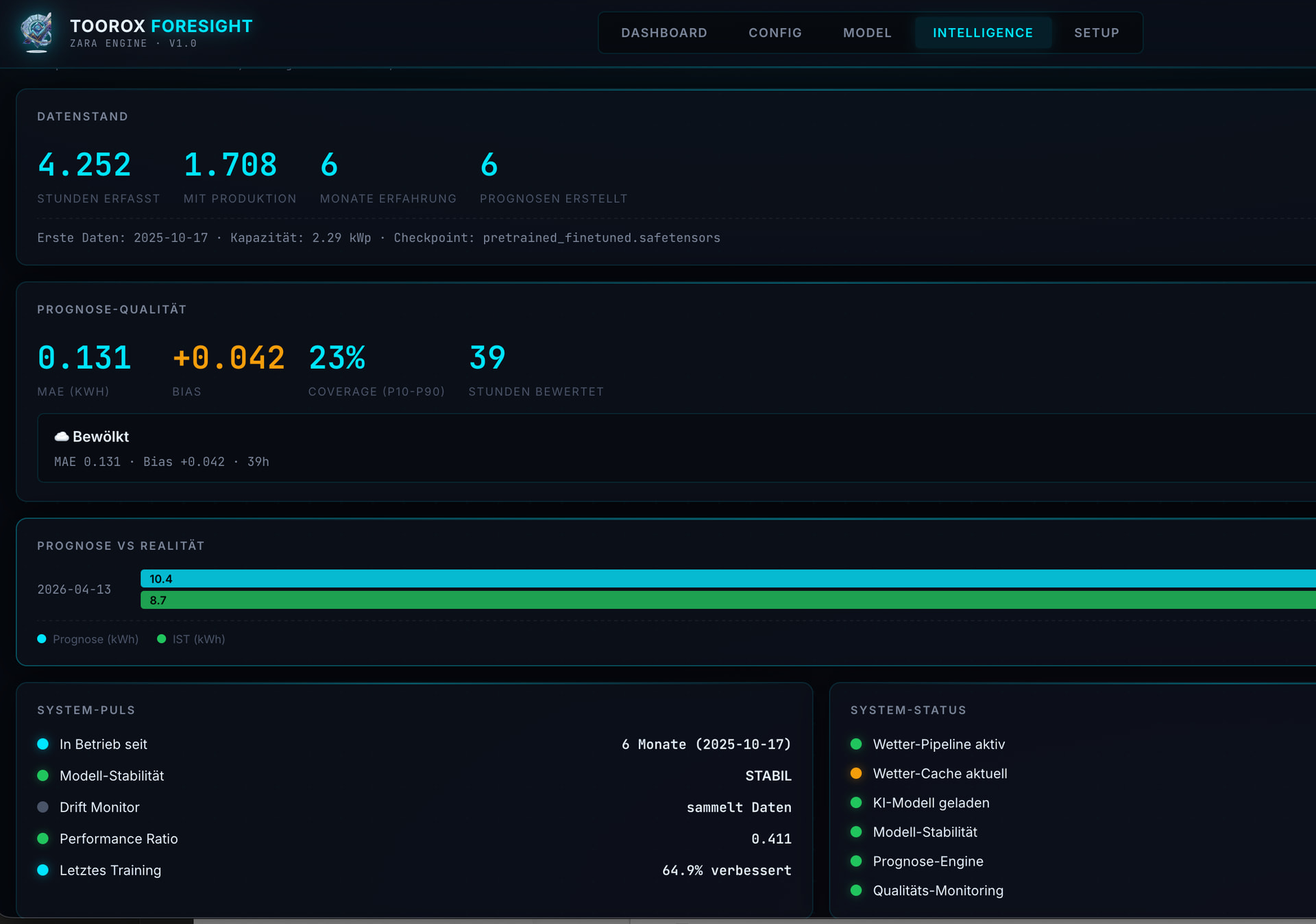
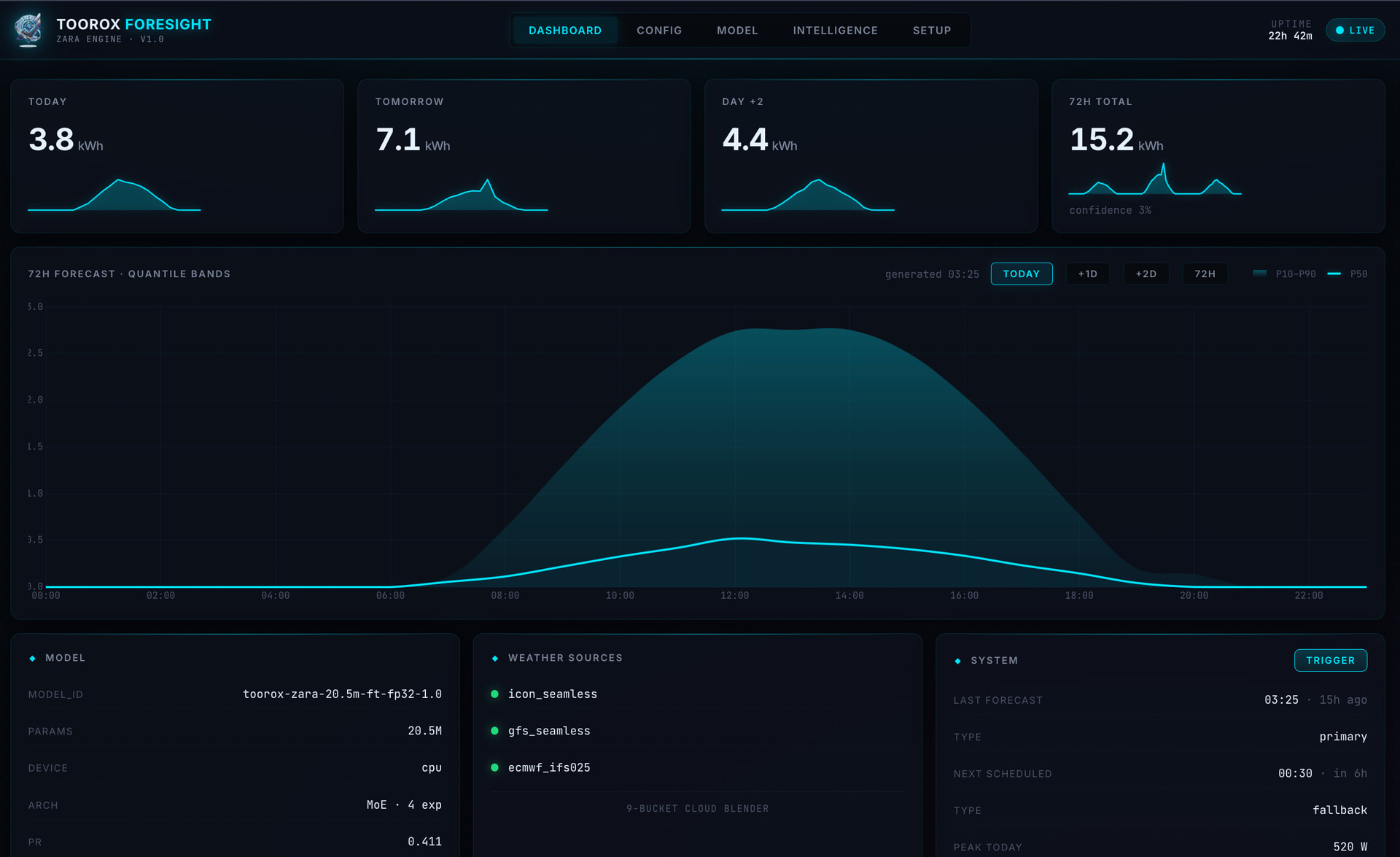
TFS Docker Standalone Version mit ZARA Multihead Transformer (BETA) 
BITTE UNBEDINGT VOR DER INSTALLATION LESEN!
Dies ist keine einfache App oder leichtgewichtiges Add-on. Ihr installiert hier einen echten, lokal trainierenden Multi-Head Transformer mit kontinuierlicher Selbstoptimierung. Der mit der Hilfe von Home Assistant Solar-Prognosen erstellt.
(Tipp: Falls ihr nicht tief im Thema seid, kopiert den technischen Teil in eine KI und lasst ihn euch erklären: „Erkläre mir bitte, was ich hier vor mir habe, worauf muss ich achten, was ist ein Transformer und was macht dieses Modell besonders?“)
Technischer Hinweis: ZARA Architecture (BETA)
ZARA steht für Zero-latency Adaptive Runtime Architecture – ein vollwertiger 3-Stream Encoder-Decoder Transformer (verwandt mit modernen LLM-Architekturen wie LLaMA), der speziell für präzise 72-Stunden-Energieprognosen und kalibrierte Unsicherheitsbänder entwickelt wurde.
Es handelt sich nicht um ein klassisches ML-Modell oder eine einfache Vorhersage-App, sondern um eine rechenintensive, sich selbst optimierende Machine-Learning-Umgebung, die lokal auf eurer Hardware läuft.
Features:
-Multi-Core Support
- CUDA, ROCm und MLX Support
- MQTT Broker
- ModBus Anbindung (im Test)
- Eigenes Backend
- Eigenes Frontent
- Mächtige Transformer KI
- 18 Jahre Wetterdaten aus einem engmaschigen Grid (ca. 50 Millionen Datenpunkte)
- 13 Jahre Klimadaten, Jahreszeiten für 180 Standorte in DE
- 18 Jahre Solardaten incl GHI und Clearsky für Europa
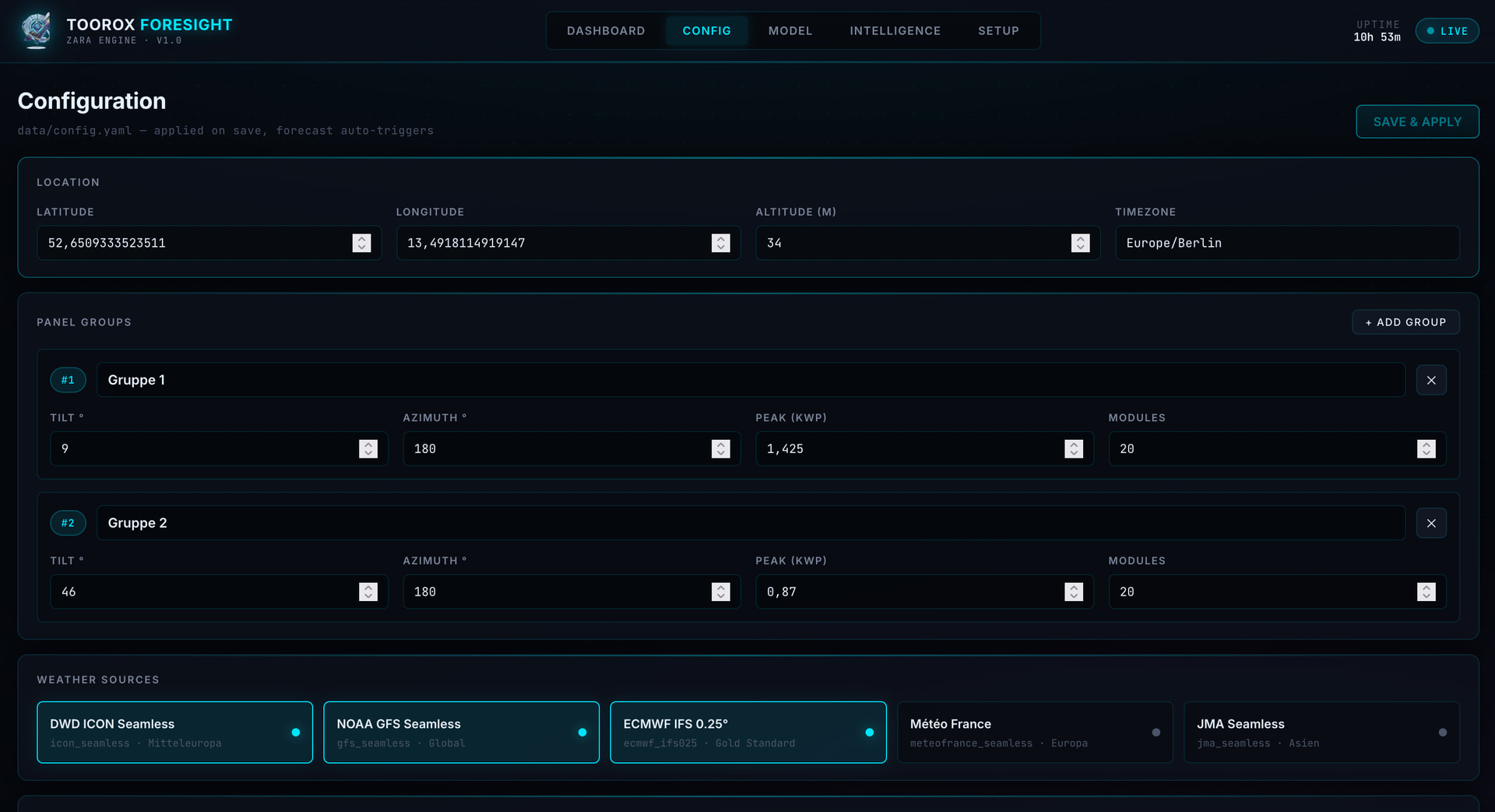
- Eigene Wetter-Engine die aus ICON, ECWMF und DWD eigenen Solarwetter-prognosen erstellt
- Selbstlernde auf den eigenen Standort
- Anbindung an Wetterstationen (via HA Sensoren)
- Mächtige Logik und Prognosekorrektur
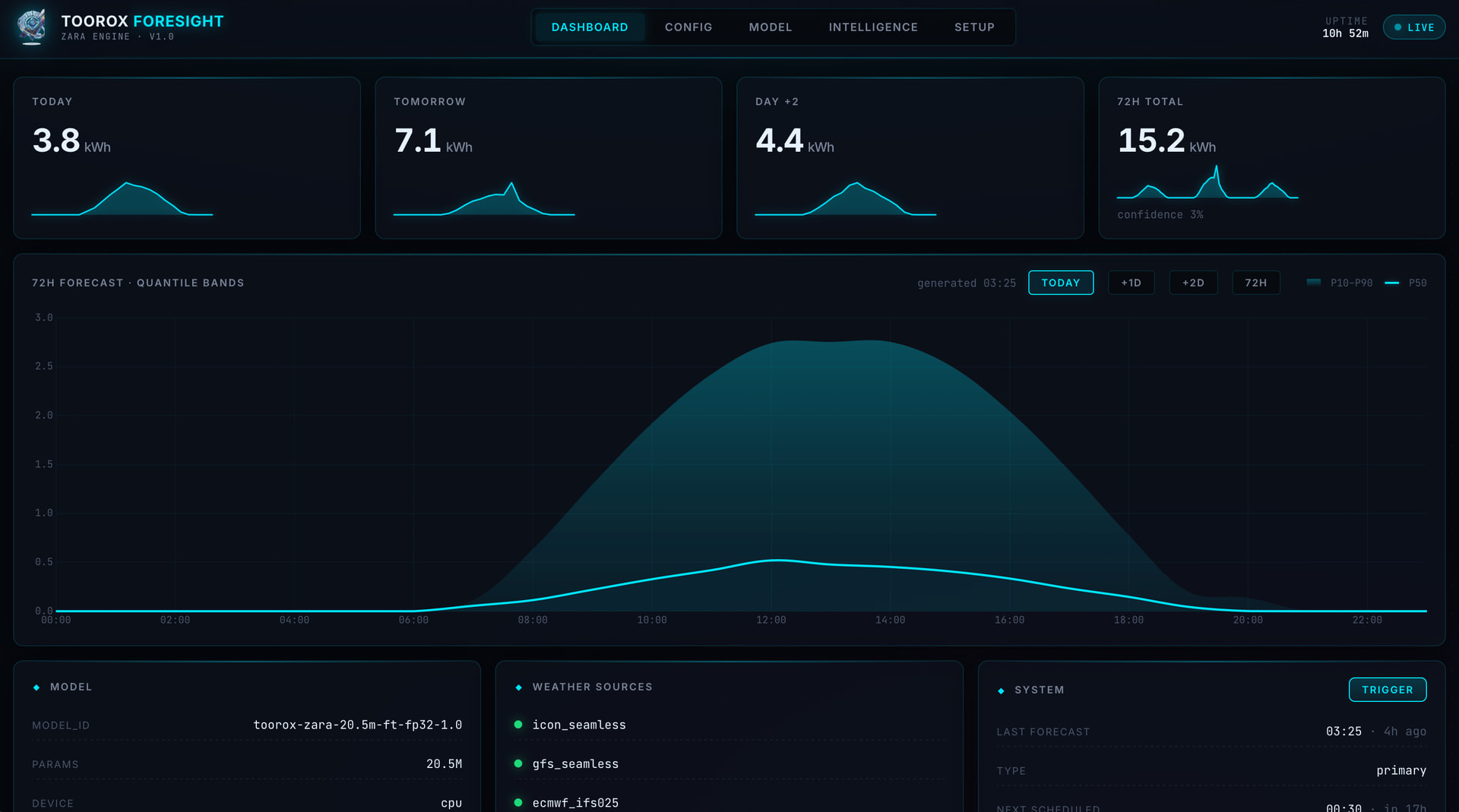
- Quantillenausgabe (P10, P50, P90)
- Medianberechung
- Drifterkennung und Emergency Training
- SQL Datenbank
- API zu Home Assistant via verschlüsseltem SSH
- Rein Lokal keine Webservices, keine Telemetrie, kein Datenabfluß
- Verschiedene Prognosemodi incl Blend-Logik
- Wetter-Blend Automatik
- Physic-Backbone
- Anti “Ich rate mal” Logik
- Insighs um die KI zu überwachen
Wichtige Systemvoraussetzungen
Diese Version benötigt dedizierte Ressourcen. Sie läuft nicht gut auf bereits ausgelasteten Systemen oder schwacher Hardware.
Empfohlen (für stabilen Betrieb):
- Mindestens 4–6 GB RAM frei (besser 8 GB+)
- Moderner x86_64-Prozessor mit AVX2-Unterstützung (Intel 6. Gen+ oder Ryzen)
- SSD/NVMe Speicher
- Dedizierte Docker-Umgebung (nicht auf einem überlasteten Mini-PC oder vollen Raspberry Pi)
Nicht empfohlen:
- Stark ausgelastete NUCs oder Einplatinencomputer
- Systeme ohne AVX2
- Weniger als 4 GB freier RAM
Technische Spezifikationen – Was macht ZARA so besonders?
-
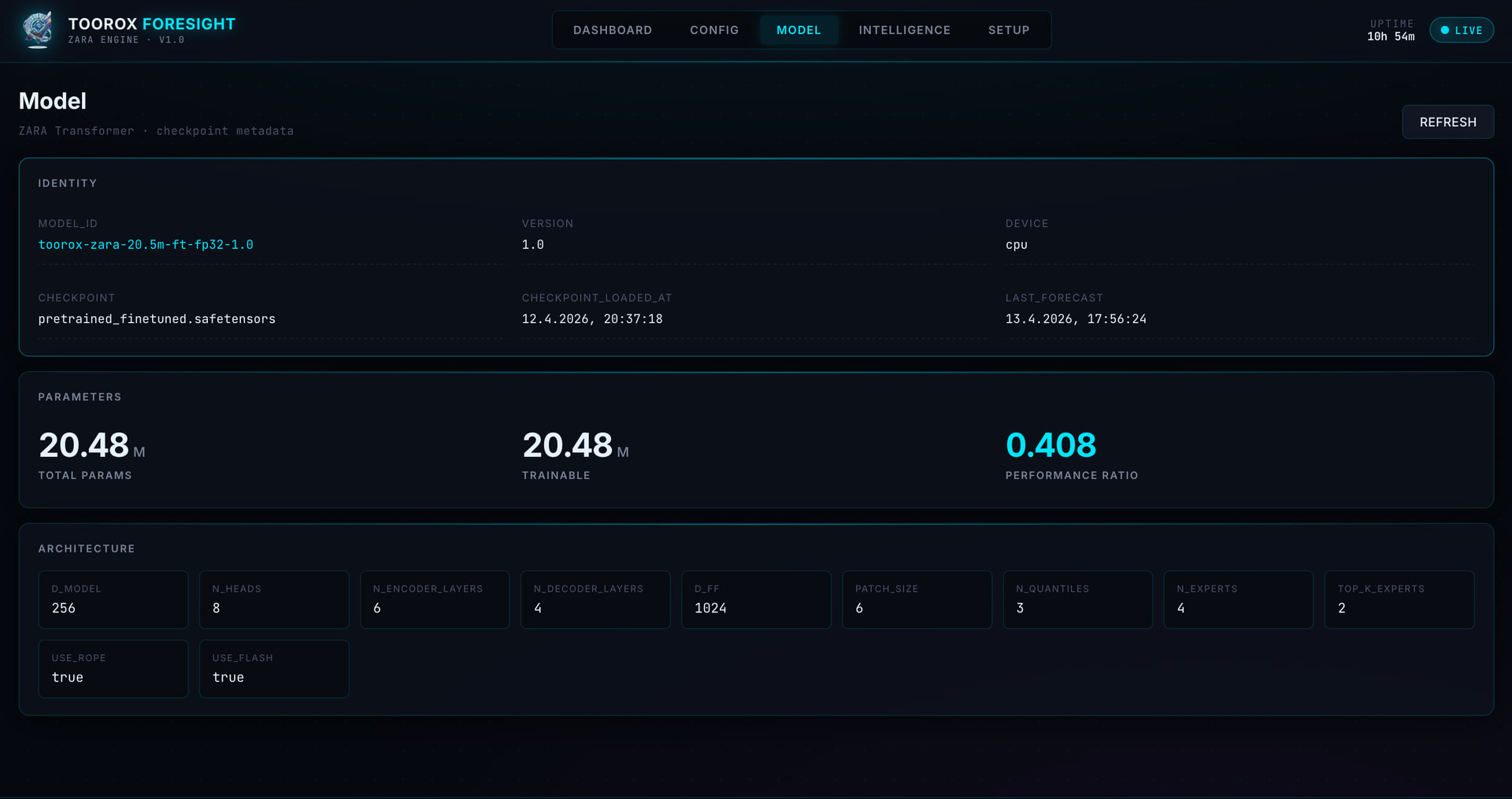
Struktur: 3-Stream Encoder-Decoder Transformer
Encoder: 6 Layer | Decoder: 4 Layer
Modell-Dimension: $d_{model}=256$, 8 Attention-Heads (4 KV-Heads mit GQA) -
Kern-Technologien:
| Komponente | Technologie | Funktion |
|---|---|---|
| Attention | Flash Attention + GQA | Reduziert KV-Cache um ~50 % bei voller Leistung |
| Positional Encoding | RoPE | Präzise relative Positionierung über lange Sequenzen |
| Activation | SwiGLU | Deutlich effizienter und stabiler als klassisches GELU |
| Routing | MoE (Top-2 aus 4 Experten) | Spezialisierte Experten für verschiedene Wetterregime |
| Normalization | RevIN | Entfernt saisonale Verschiebungen automatisch |
| Physics Layer | Constraint Layer | Verhindert physikalisch unmögliche Vorhersagen (z. B. Strom nachts) |
| Output | Quantile Regression | Liefert P10 / P50 / P90 Konfidenzintervalle statt einfacher Punktwerte |
Adaptivität & Lernen:
- Vollkommen lokal, keine Cloud, keine externen APIs
- Täglich: Automatische Prognosegüte-Analyse
- Wöchentlich: Micro-Finetuning
- Monatlich: Full Retrain gegen Model Drift
- Integrierte Drift Detection startet bei Bedarf automatisch Korrektur-Training
Fazit: ZARA ist ein hochmodernes, aufgabenspezifisches neuronales Netz, das echtes Kontext-Reasoning über Wetter- und Produktionsmuster betreibt – weit über das hinaus, was klassische Solarprognose-Modelle leisten können.
Installation – TFS Docker Standalone (BETA)
Linux (Bare Metal / VM)
- Docker installieren (falls noch nicht vorhanden):
curl -fsSL https://get.docker.com | sh
- Image entpacken und laden:
docker load < toorox-foresight-beta.tar.gz
- Container starten:
docker run -d \
--name toorox-foresight \
--restart unless-stopped \
-p 8780:8780 \
-v toorox_data:/data \
-v ~/.ssh:/host_ssh:ro \
toorox-foresight:latest
- Im Browser öffnen:
→ http://<DEINE-IP>:8780
Der Setup-Wizard führt euch durch alles Weitere.
Proxmox
Option A – LXC (empfohlen, leichtgewichtig):
- Neuen LXC-Container erstellen (Debian 12 Template)
- 4 GB RAM, 8 GB Disk, 2 Cores
- Feature
nesting=1aktivieren - Dann im LXC die gleichen Docker-Befehle wie oben ausführen
Option B – VM:
- Normale VM mit Debian 12 oder Ubuntu 24.04
- Mind. 4 GB RAM, 16 GB Disk, 2 Cores
- OS installieren → dann Docker-Befehle
Nach dem Start
- Browser:
http://<IP>:8780 - Setup-Wizard starten
- SSH-Zugangsdaten zu eurem Home Assistant eingeben → Testverbindung
- „Import Configuration“ klicken → TFS liest automatisch alle Daten aus der SFML-Datenbank (Anlage, Panelgruppen, Sensoren, Standort etc.)
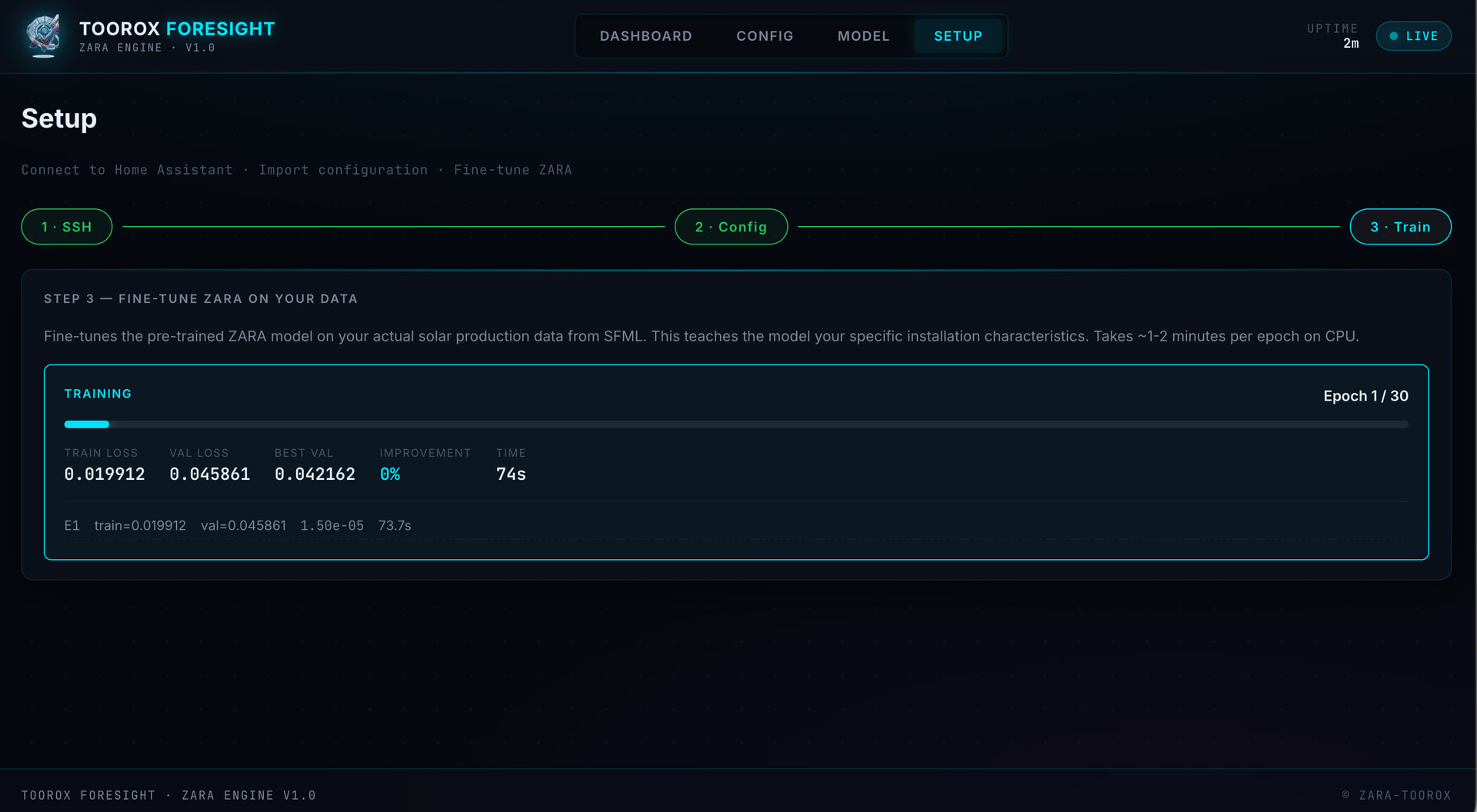
- „Start Fine-Tuning“ → ZARA lernt eure Anlage (ca. 1–2 Minuten pro Epoch)
- Fertig – die Forecasts laufen automatisch und werden kontinuierlich optimiert
Fragen, Probleme oder Erfahrungsberichte gerne hier im Thread!
Bitte keine Fragen nach " Wie installiere ich ein Docker-Image"
Viel Spaß mit ZARA!
RELEASE: 16.04.2026 (BETA 1)
Fuel my late-night ideas with a coffee? I’d really appreciate it — keep this project running!
![]()