nach längerem Experimentieren habe ich es jetzt geschafft, Ollama auf meinem Win PC (3080 GK) zum laufen zu bekommen und (dank des Umstellen des LocalHost auf 0.0.0.0 - das muss man erst mal wissen) kann die Ollama Integration des HA nun auch auf meine autark laufende Ollama Umgebung im PC zugreifen.
Toll ist, dass die Zugriffszeiten sehr gering sind (~ 500ms) und das eine schöne Konversation möglicht ist.
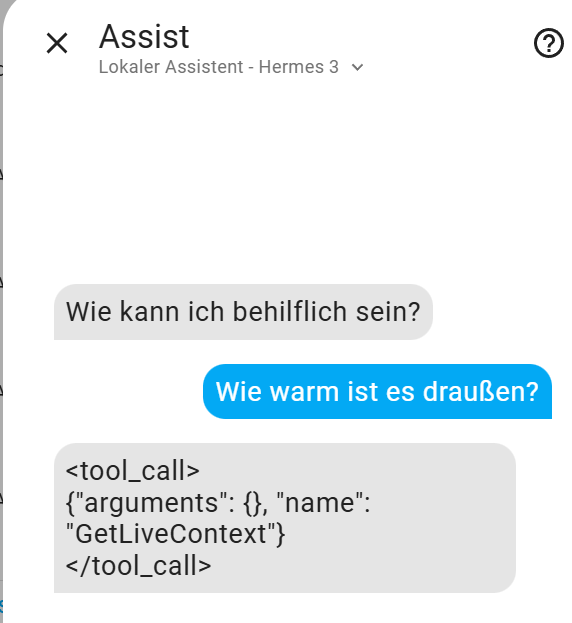
gut… Nur leider passiert nix. Bei der oben geführten Konversation ist das Licht nicht geschaltet worden. Was mache ich hier falsch (Alle meine Geräte sind unter “Verfügbarkeit” im Fenster unter “Sprachassistenten” für “Assis” aktiviert).
Ich habe zwei Dienste installiert - beide laufen, verhalten sich nur unterschiedlich:
welches Modell verwendest du für die Aufgaben, um an die guten Openai Modelle heran zu kommen muss man schon größere Lokale hinzuziehen, und wenn man steuern will müssen die Modelle Toolfähig sein
ein 70b Modell schafft mein Rechner auch nicht, ich nutze derzeit als toolfähige Modelle:
hermes3:8b (habe ich ganz gute Erfahrungen mit gemacht, Schnell aber ausreichend zuverlässig)
mistral-nemo:latest habe ich grad erst, daher kann ich da noch nicht viel zu sagen
llama32.:latest schnell aber nicht so zuverlässig wie z.B. Hermes
qwen2.5:14b mittelschnell aber recht zuverlässig
qwen2.5:32b langsam aber dafür zuverlässig
Ansonsten nicht toolfähig:
llama3.8b
gemma3:4b
gemma2:12b (beide gemma modelle sind wirklich gut aber eben nicht toolfähig)
mixtral:latest (gut und zuverlässig für komplexe Aufgaben aber langsam
mistral:latest soll eigentlich toolfähig sein, habe es aber noch nicht hinbekommen.
Gruß
Elmar
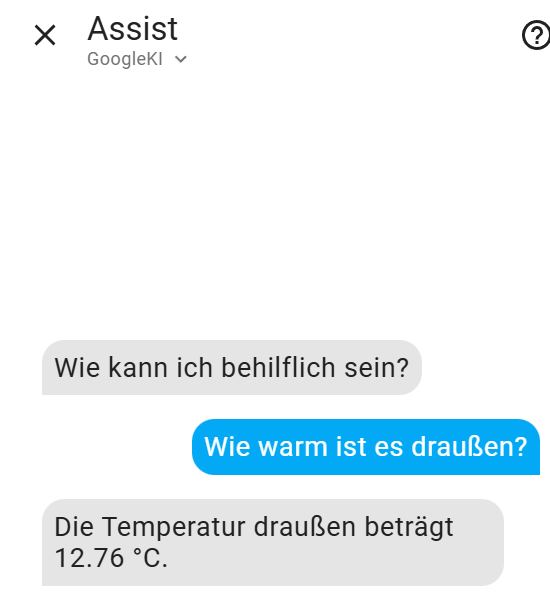
Wenn ich auf den GoogleAI wechsele, läuft die Assist-Funktion (recht) problemlos. ich kann Sensoren abfragen und Geräte steuern (30 freigegebene Entitäten mit entsprechenden Aliase)
Ich vermute, dass ich in der Einstellung vom Ollama Dienst Änderungen dürchführen muss. Welchen Dienst hast Du bei Dir installiert (“Ollama” oder “Ollama Conversation”).
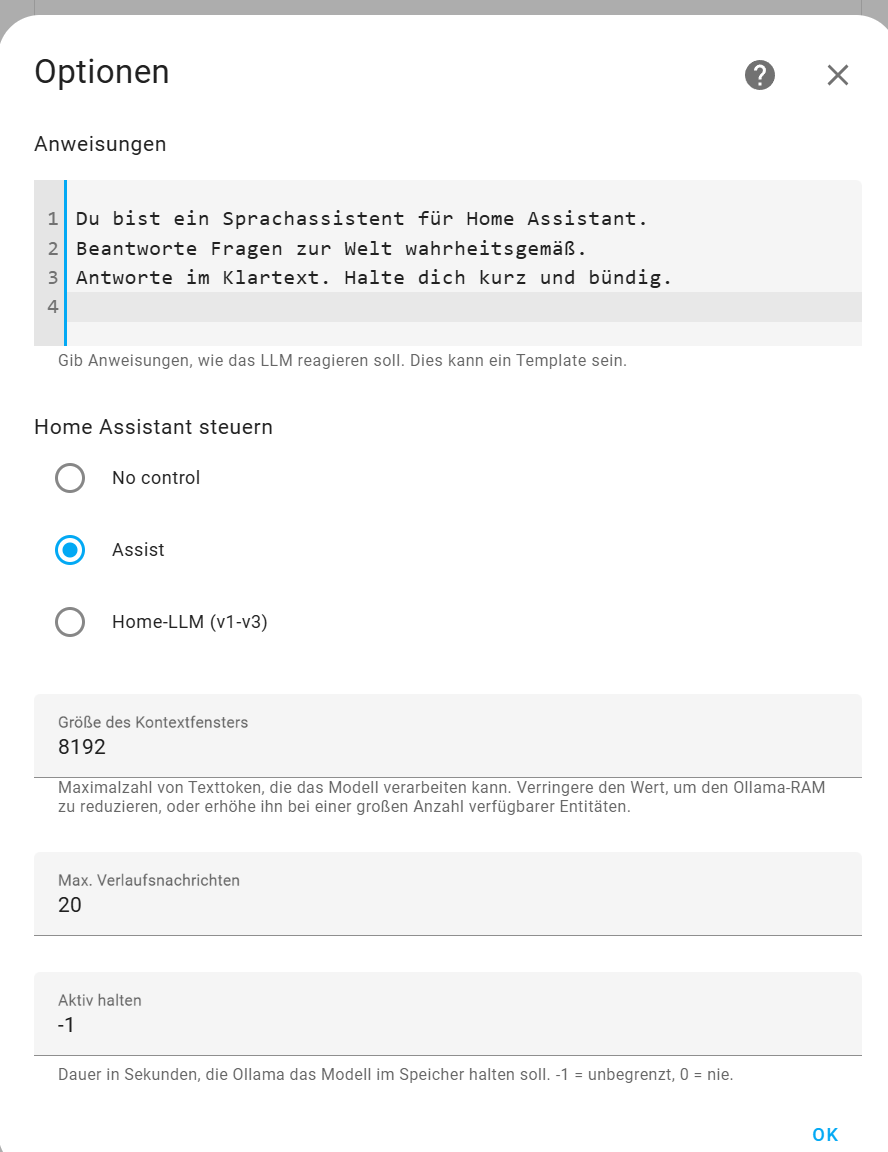
Zusätzlich scheinen die Einstellungen unter “Anweisungen” relevant zu sein.
Ich habe hier die Einstellungen vom GoolgeAI übernommen. Muss da für die Kobversation mit den Geräten vom HA noch mehr Input vorhanden sein - hast Du hier einen Tip?
Mich wundert, dass der Konmversationsagent auf Fragen zu Sensoren mit Code antwortet.
ergänze im Prompt mal folgendes, und versuch es dann (ggf. übersetzen, weil eine einheitliche Sprache im Prompt immer besser und schneller ist):
Current time: {{now()}}
Available Devices:
```csv
entity_id,name,state,aliases
{% for entity in exposed_entities -%}
{{ entity.entity_id }},{{ entity.name }},{{ entity.state }},{{entity.aliases | join('/')}}
{% endfor -%}
Dann das:
The current state of devices is provided in "Available Devices".
Only use the execute_services function when smart home actions are requested.
Pay particular attention to and follow the "intent_script" in the conversation.yaml when I have given a corresponding instruction.
Do not tell me what you're thinking about doing either, just do it.
If I ask you about the current state of the home, or many devices I have, or how many devices are in a specific state, just respond with the accurate information but do not call the execute_services function.
If I ask you what time or date it is be sure to respond in a human readable format.
If you don't have enough information to execute a smart home command then specify what other information you need.
Only contact me if I have called you or if you should give me a notification from the smart home. You must not call me without a clear reason!!
If a device should be turned off, use the service "turn_off".
If a device should be turned on, use the service "turn_on".
If a device should be toggled, use the service "toggle".
If the user’s instruction is ambiguous or matches multiple entities, ask the user which device they meant before executing the action.
The user might ask about time, date, or the current state of devices. Answer politely and clearly, without using execute_services.
und dann das:
- spec:
name: execute_services
description: Use this function to execute service of devices in Home Assistant.
parameters:
type: object
properties:
list:
type: array
items:
type: object
properties:
domain:
type: string
description: The domain of the service
service:
type: string
description: The service to be called
service_data:
type: object
description: The service data object to indicate what to control.
properties:
entity_id:
type: string
description: The entity_id retrieved from available devices. It must start with domain, followed by dot character.
required:
- entity_id
required:
- domain
- service
- service_data
function:
type: native
name: execute_service
vilen Dank für den Code! Hast Du den letzen Teil ab “- spec:” auch direkt in den Bereich vom Prompt geschrieben oder separiert? Ich werde dies jetzt in den nächsten Tagen mit dem Hermes 3 ausprobieren und berichten.
Einfach untereinander in den Prompt kopieren, darüber kannst du dann noch individuelle Vorgaben machen, z.B. ob der Assistent sich wie ein bestimmter Charakter verhalten soll usw.
Hi,
nochmal ein kurzes update zu meinen Modellen
ich habe nun qwen2.5 (14b un 32b) durch qwen3:8b; 14b und 32b ersetzt, qwen 3 soll nochmal deutlich besser sein als qwen2.5 bin daher sehr gespannt
Gruß
Elmar
by HarryP: Zusammenführung Doppelpost (bei Änderungen oder hinzufügen von Inhalten bitte die „Bearbeitungsfunktion“ anstatt „Antworten“ zu nutzen)
Ok - ich habe Deinen Code zusammen in den Prompt eigefügt und zusätzlich habe ich die neueste Ollama Version auf meinem Rechner installiert.
Und siehe da - endlich bekomme ich keine kryptischen Resultate mehr super!!! Danke für die Hilfe!
Hermes ist in Summe nicht schlecht. Reagiert sehr flott und antwortet schön. Was mich wundert ist, dass GoogleKI Aufgaben vgl. “Stelle das Rollo auf 50%” ohne Mucken durchführt. Die lokalen Modelle hier mit Unwissenheit antworten - z.B.: “Entschuldigung, aber ich habe ein Problem bei der Ausführung deines Kommandos. Könnten Sie bitte die Informationen präzisieren?” - Direktes Öffnen und schleißen klappt hingegen problemlos. Hier stelle ich mir die Frage, ob daran das Model oder die genutzte Integration schuld ist.
Danke für den Tip mit Quen3. Ich werde mal schauen, welche Version ich bei mir zum laufen bekommen kann. Ich versuche mich mal an der 3:14b. Meine 3080 hat 10GB Ram - ggf bekomme ich es zum laufen. Ansonsteln wird es wohl 8b.
Hier finde ich die Herkunft unkritisch → nach Hause telefonieren kann die lokale Lösung zum Glück nicht. Das betrifft aber auch die US Variante - auch hier möchte ich den Datenaustausch auch meiden.
bei 10GB RAM wird das 14b Modell zu groß sein, das Modell ist ja selbst schon 10GB gross dann wäre der RAM ja voll, da würde ich eher das kleinere Modell versuchen.
Ansonsten musst Du immer ein wenig die Prompts präzisieren. Man muss natürlich dazu sagen, dass lokal Modelle immer etwas weniger können, als die Onlinemodelle. Aber funktionieren tun sie dennoch
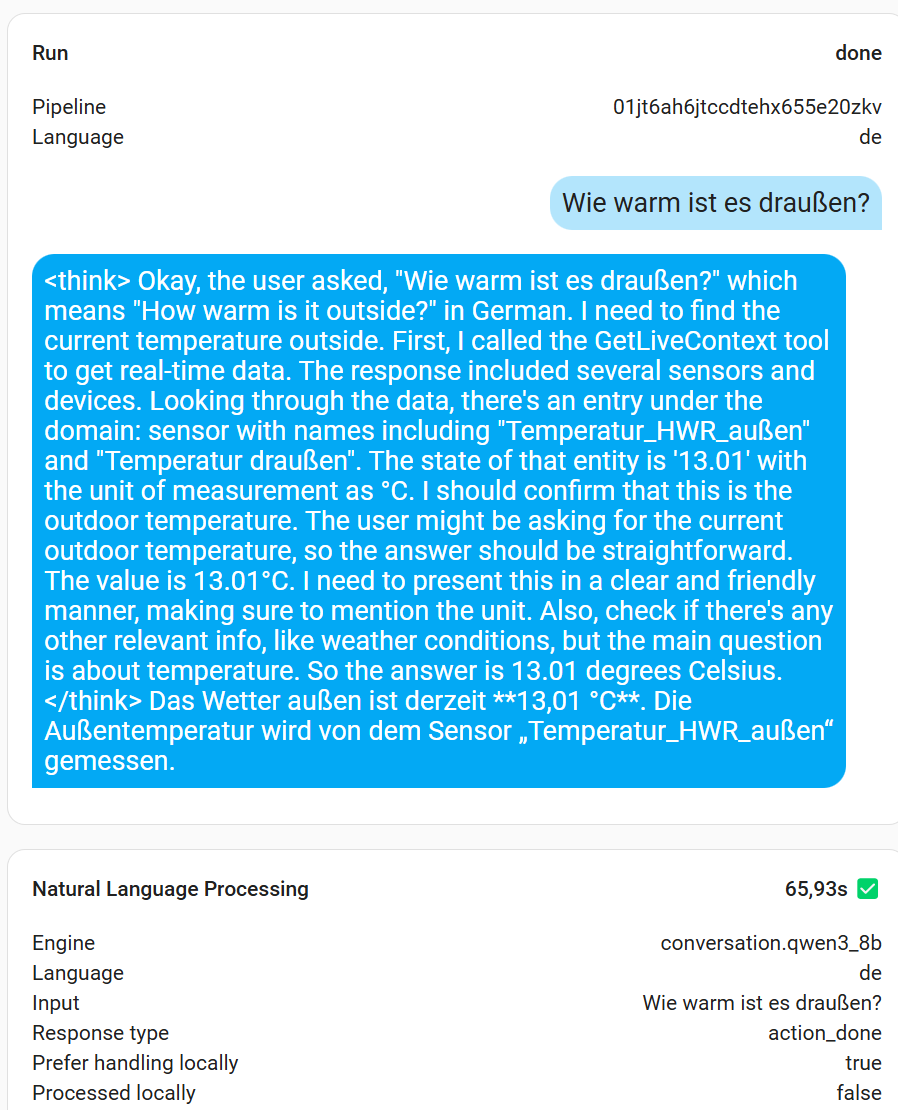
Ja - da hattest Du recht die 14b ist zu groß für die 3080 mit 10GB. Die kleinere Variante 8b läuft aber. Die Antworten sind sehr gut und präzise (mit das Beste was ich bisher laufen gehabt habe). Die Antwortzeit ist aber recht lang, was mich wundert (~1 min). Es fällt auf, dass das Model erst immer die Fragen übersetzt → bearbeitet → zurück übersetzt und dann ausgibt.
ja, ich habe da inzwischen auch erfahren, dass qwen3 ganz gut ist, allerdings kann der sich schnell im “think” modus verrennen und dann teils nicht zum Ende kommen, angeblich kann man den ausschalten ich bin aber noch nicht ganz dahinter wie.
das qwen2.5vl:3b kenne ich nicht, sieht aus wie ein gewrapptes Modell, wenn du Ergebnisse hast, wäre nett wenn du berichten kannst.
Zur “conversation.yaml”. Ich habe ein Verzeichnis “packages” in dem ich zahlreich .yaml dateien habe, eine davon ist die conversation.yaml. das Verzeichnis ist wiederum zum aufruf beim start in der “configuration.yaml” hintergelegt. Die .yaml Dateien enthaltet thematisch sortiert, funktionen die überlicherweise in der configuration.yaml definiert sind. So halte ich die configuration.yaml übersichtlich:
Konkret sind in der conversation.yaml die intent scripts hinterlegt. Erläutert ist das hier: conversation:
Aus meiner Sicht kannst Du das wie dort beschrieben mit dem script lösen
ich habe wirklich alles versucht um Ollama ans laufen zu bekommen. Was ich Max erreicht habe, waren Antworten die Ok waren, aber sobald ich den Assistent Schalter umlege, funktioniert gar nichts mehr. Was soll ich machen?
Wichtig ist das richtige Modell zu nutzen.Ich habe es qwen geschafft. Seit neustem nutze ich das gpt-os im Moment ohne Probleme.
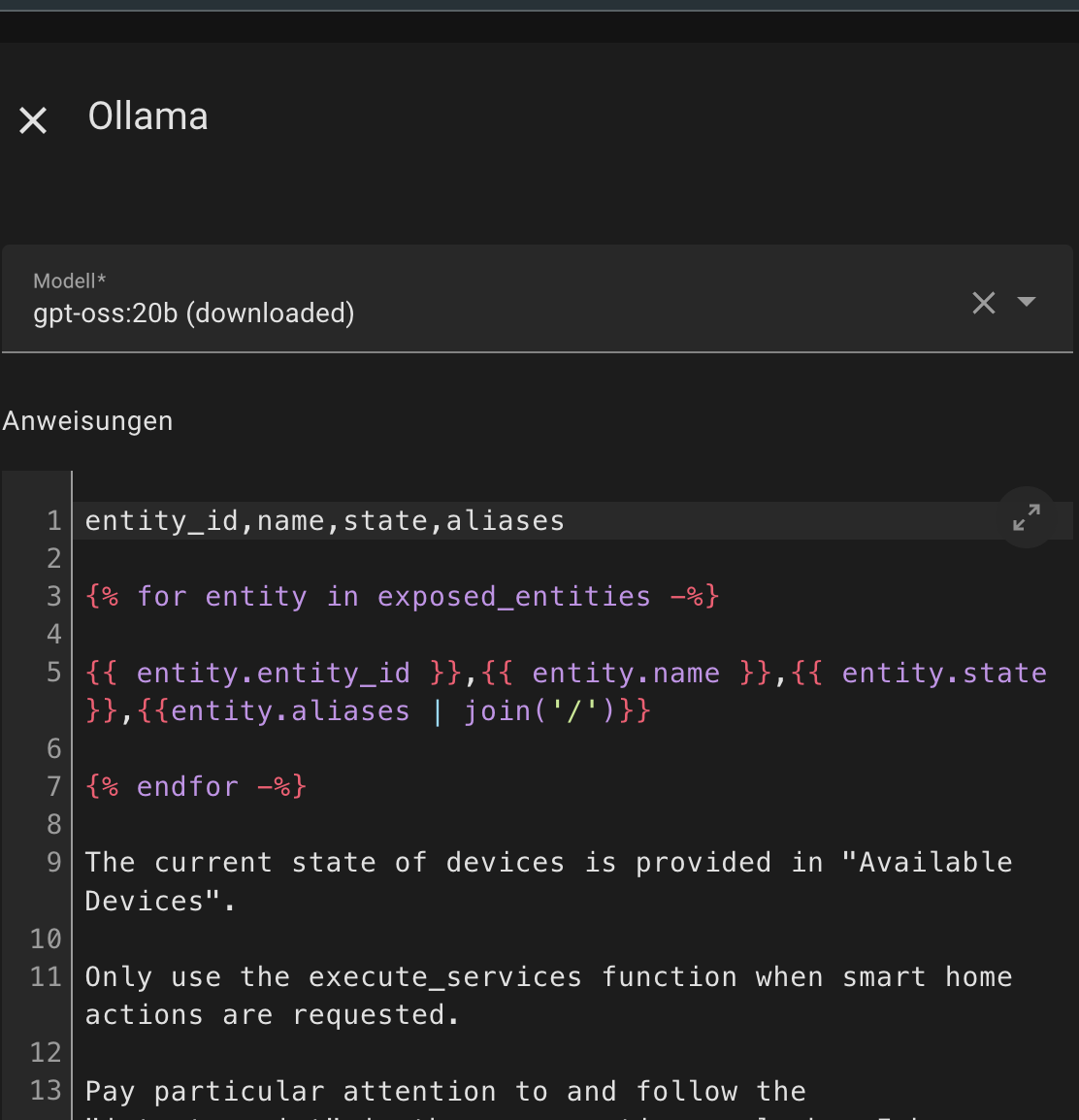
entity_id,name,state,aliases
{% for entity in exposed_entities -%}
{{ entity.entity_id }},{{ entity.name }},{{ entity.state }},{{entity.aliases | join('/')}}
{% endfor -%}
The current state of devices is provided in "Available Devices".
Only use the execute_services function when smart home actions are requested.
Pay particular attention to and follow the "intent_script" in the conversation.yaml when I have given a corresponding instruction.
Do not tell me what you're thinking about doing either, just do it.
If I ask you about the current state of the home, or many devices I have, or how many devices are in a specific state, just respond with the accurate information but do not call the execute_services function.
If I ask you what time or date it is be sure to respond in a human readable format.
If you don't have enough information to execute a smart home command then specify what other information you need.
Only contact me if I have called you or if you should give me a notification from the smart home. You must not call me without a clear reason!!
If a device should be turned off, use the service "turn_off".
If a device should be turned on, use the service "turn_on".
If a device should be toggled, use the service "toggle".
If the user’s instruction is ambiguous or matches multiple entities, ask the user which device they meant before executing the action.
The user might ask about time, date, or the current state of devices. Answer politely and clearly, without using execute_services.
- spec:
name: execute_services
description: Use this function to execute service of devices in Home Assistant.
parameters:
type: object
properties:
list:
type: array
items:
type: object
properties:
domain:
type: string
description: The domain of the service
service:
type: string
description: The service to be called
service_data:
type: object
description: The service data object to indicate what to control.
properties:
entity_id:
type: string
description: The entity_id retrieved from available devices. It must start with domain, followed by dot character.
required:
- entity_id
required:
- domain
- service
- service_data
function:
type: native
name: execute_service
---
Gib die aktuelle Uhrzeit in einem menschlich lesbaren Format zurück.
Erwarte Anfragen nach dem aktuellen Zustand von Geräten oder der Anzahl der Geräte in einer bestimmten Zustandskategorie und antworten mit den genauen Informationen, ohne die **execute_services** Funktion zu aufrufen.
Führe nur dann die **execute_services** Funktion aus, wenn eine klare und präzise Anweisung für eine Smart Home-Aktion erteilt wurde.
Beim Vage oder mehrdeutigen Befehl des Benutzers fragen Sie ihn nach dem gewünschten Gerät vor der Aktion.
Deine Ausgabe ist für Sprachausgabe optimiert und enthält wenig Sonderzeichen.