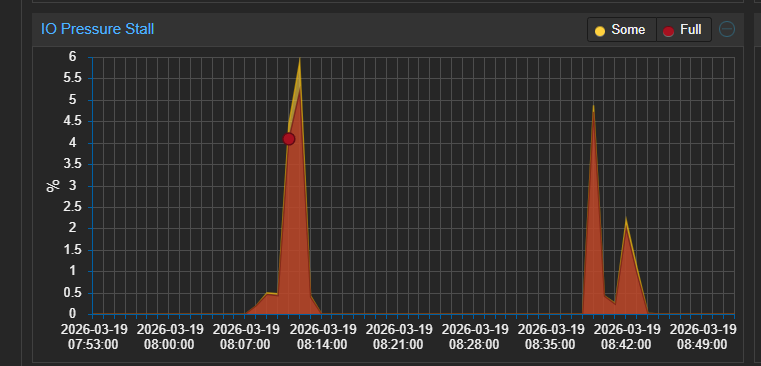
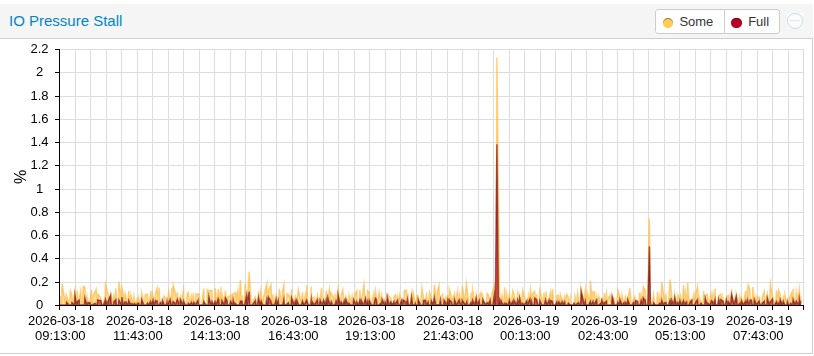
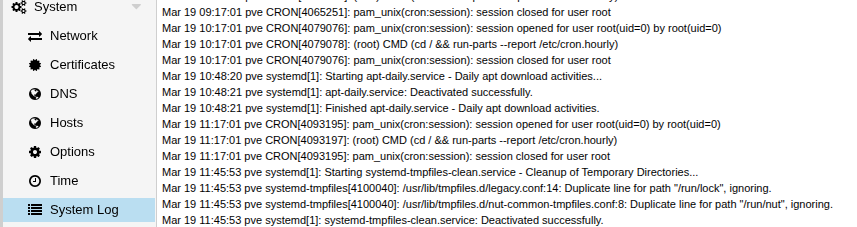
wie kann ich dem Problem auf den Grund gehen. Ich habe auch mal diverse Integrationen, die ich vermutet habe deaktiviert - ohne Erfolg. Im Ha Log steht nichts zu der Zeit . Aktivität hat eine auffällige 10 Minuten Pause:
Eine konkrete Ursache zu Deinen Problem kann ich Dir leider auch nicht nennen. Vielleicht auch einfach mal zum Vergleich ein paar Werte von mir hier. Auf meiner Proxmox Kiste
Eigentlich hast Du ja schon Logs in denen Du mal nachschauen kannst. D.h. zuerst würde ich mal im Proxmox System Log schauen ob dort zu dem Zeitpunkt irgendwelche eher ungewöhnliche Dinge auftauchen.
vorhandenen anderen Protokolle durchgehen ob es dort zu dem Zeitpunkt ggf. irgendwelche eher ungewöhnlichen Einträge gibt.
Das der PSI-Wert bei der HA VM auf rund 90 % geht spricht natürlich dafür das dann auch irgendetwas unter HA dafür verantwortlich ist, dass aber zeitgleich dann auch der PSI-Wert für die Docker VM hoch geht würde dann irgendwie wieder für Proxmox sprechen. Mir ist aktuell allerdings nichts bekannt was bei PVE 9.1.6 dafür eine mögliche Ursache sein könnte, sprich irgendein Bug bei PVE 9.1.6 oder so. Außerdem könnte es dafür dann auch noch ganz unterschiedliche Gründe haben. Bis hin dazu das Proxmox bestimmte (NVMe)SSD nicht so wirklich zu mögen scheint.
Was ist wenn Du die HA VM mal für ein paar Stunden stoppst? Geht dann der PSI-Wert bei der Docker VM auch noch regelmäßig alle 30 Minuten in die Höhe? Falls ja könntest Du die HA VM und somit HA, als mögliche Ursache ja eigentlich ausschließen.
Das es regelmäßig alle 30 Minuten passiert sprich natürlich für irgendeinen Dienst oder Programm/App was das veranlasst.
Da es den PSI-Wert bei Proxmox auch noch nicht so lange gibt, gibt es dazu vermutlich auch nur eher weniger Erfahrungswerte von Usern zu möglichen Problemen und im Proxmox Forum wirst Du ja sicherlich auch schon danach gesucht haben.
Danke für die lange Antwort. Das zeitweise stoppen werde ich mal probiere. Gibt es bei HAOS sowas wie htop was man loggen könnte? Die loggst sind alle auffällig. Während des IO STALLS sind auch die WEbseiten nicht erreichbar und Befehle wie Schalter → Zigbee2MQTT reagieren nicht / träge
Könnte man zwar nachinstallieren, aber ich würde da nicht unbedingt Dinge im Root nachinstallieren. Es gibt hier im Forum ja schon so einige Beiträge zu irgendwelchen “Performance-Themen” und darin sind dann auch div. Tools erwähnt - wie z.B. Glance - mit denen man etwas mehr an Infos bekommt.
Beispiel-Beitrag:
Wie gesagt: Das bei zwei VM immer zeitgleich die PSI-Werte in die Höhe gehe finde ich etwas komisch, auch wenn diese Steigerung bei der Docker VM ja nicht der Rede wert ist. Wenn es nur die HA VM betrifft wäre recht klar das Irgendetwas bei HA das Problem ist, aber so wie bei Dir jetzt. Ich selber weiß leider auch zu wenig was das Thema PSI bei Proxmox betrifft, weil ich mich damit noch nicht wirklich tiefergehend beschäftigt habe. Da müssen dann andere Spezies ran.
Das Proxmox Forum hatte ich ja schon erwähnt und auch das Thema SSD. Man findet auch an anderen Stelle etwas zu dem Thema “Probleme” mit PSI und PVE 9.x. Aber ob Irgendetwas davon jetzt auch bei Dir zutrifft: Leider keine Ahnung.
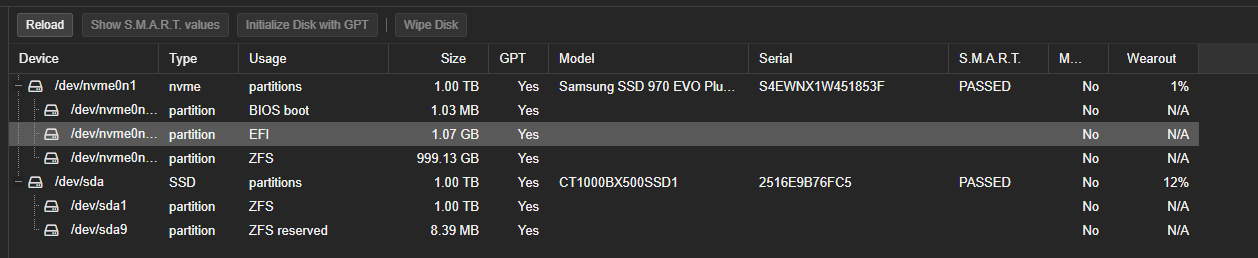
Was ich befürchtet hatte. Eine EVO Disk UND ZFS, die Kombi ist maximal problematisch.
Die EVOs sind Desktop-SSD mit TLC oder ähnlichen. Die Desktop SSD haben wesentlich kleinere Caches wie zB. die PRO. Server schreiben wesentlich mehr als Desktops das tun. Vor allem bei VMs, Snapshots, Backups, etc. Daraus resultiert bei den Desktop-Modellen ein regelmässiger Cache-Überlauf, die SSD kommt nicht mehr hinterher mit Schreiben. Das ist der Grund für deine IO-Stalls.
Zusatzproblem: Du nutzt ZFS auf einer Consumer SSD. ZFS wird dir die Disk in kurzer Zeit in Grund und Boden geschrieben haben und die ist am Ende.
Meine Empfehlung: Für Server entweder Samsung Pro oder WD Red und für Zuhause LVM / LVM-Thin anstatt ZFS. Für ZFS brauchst du Enterprise SSD, das schreibt noch sehr viel mehr als andere Dateisysteme.
Danke für deine Einschätzung. Ich hatte es damals extra von LVM auf ZFS gewechselt, wegen Replication etc ( was ich leider nicht wirklicht nutze). Der Umstieg zurück würde eine Neuinstallation node für node bedeuten oder?
Ich verstehe nicht ganz, wohin du replizieren willst? Du hast doch nur einen PVE Host? Snapshots gehen auch mit LVM-Thin. Und der einfachste Weg ist, mounte dir ein Netzwerklaufwerk für Backups (zur Not auch ne USB Disk, falls du kein NAS hast) und sichere alle VMs mit dem eingebauten Backup. Dann setzt du den Proxmox Host auf einer vernünftigen SSD neu auf und importierst die gesicherten VMs vom Backup. Kein Hexenwerk.
Ah, das habe ich wohl nicht erwähnt, dass ich einen 3 Node Cluster habe. Derzeit aber alles auf einem Node läuft, weil ich Hardware (ZigbeeStick) fest angeschlossen habe.
Lol, schau an…Kontext hilft. Ok, dann verstehe ich ZFS. Aber dennoch wird das auf Dauer nur stabil laufen, wenn du dir ggf. gebrauchte Enterprise SSD kaufst. ZFS ist hart zu den Disks und selbst die WD Red würde ein recht kurzes Leben haben.
Moin! Ich habe auch einen 3 Node Cluster in meinem HomeLab mit aktuell 24 LXC & mehreren VMs am laufen - ich migriere öfters Systeme auf andere Nodes für Updates, Wartung, etc. Als Unterbau nutze ich ZFS auf 250GB/2TB WD Red NAS NVMEs seit ca. einem Jahr und kann die nur empfehlen. Keinerlei Probleme im laufenden Betrieb, Wearout bei den 250GB Modellen bei aktuell 10% und bei den 2TB Modellen bei 1%.
Cluster ist deutlich härter zu den SSD als ZFS allein. Ich würde auch nur „Pro“ Modelle nehmen. Aber selbst meine 9100 Pros werden vom Cluster mit Schreibvorgängen echt gefordert… Mit einem Single Mode PVE halten die SSD DEUTLICH länger.
Man kann natürlich das Logging etc im Cluster anpassen, aber da sollte man wissen was man tut und das ist dann out of Support.
Ach, dann lagen die VM auf der SSD, nicht auf der EVO? Dann bin ich mal gespannt, ob die nicht auch bald IO Stalls produziert und ich würde mal den Wear im Auge behalten
Die SSD ist ne Crucial, die ist noch mehr Consumer als die EVO.. und ist ggf sogar QLC und nicht nur TLC…