Würdet ihr mir bitte erzählen welche Version von InfluxDB ihr mit einem einfachen HA OS benutzt? Soweit ich sehe gibt es inzwischen ja sogar eine dritte Ausführung.
Der Grund meiner Anfrage ist, dass ich mich derzeit an InfluxDB 2 “abarbeite“. Die Installation steht, das Ding scheint auch ohne Probleme in den Logs zu laufen, nur zu sehen gibt es nichts. Auf der Suche nach Erklärungen dafür habe ich mir die Videos von Alkley und Simon angeschaut. Dabei habe ich gesehen, dass die dort jeweils gezeigte Version 1 wesentlich einfacher zu händeln scheint.
Jetzt bin ich halt verunsichert und würde am liebsten die 2 runter nehmen und tatsächlich die 1 einrichten. Nur hat das einen Sinn? Mein Ziel ist natürlich noch Grafana, wenn ich mich in InfluxDB eingerichtet habe.
Was empfehlt ihr mir? Ich freue mich auf eure Antworten.
Influx selber läuft auf einem separaten Raspi zusammen mit Grafana mit einer SSD für den Influx Storage, damit nicht die SD-Card mit ständig Writes bombardiert wird.
Ein Migration nach InfluxDB 3 Core habe ich aktuell nicht vor, so lange das noch einigermaßen Support da ist. Ich habe mal mit Version 1 angefangen, dann lief der Support aus und die Migration war mir nicht möglich. Ich habe dann V2 neu aufgesetzt. Einen downgrade würde ich nicht empfehlen.
Danke für deine Einschätzung. Ich dachte ja bisher eigentlich auch, dass Version 2 zu diesem Zeitpunkt die beste Entscheidung ist.
Also, die reine Installation steht. Einträge in configuration- und secrets.yaml gemacht nach einer guten Dokumentation, die ich hier durch die SuFu fand. Die Entitäten, die mir wichtig sind, in dem Eintrag der entsprechenden Yaml eingebunden. Zwei Tokens, eines davon das mit allen Rechten. Alles gut.
Mein Problem ist, dass nur englischsprachige Dokumentationen über diesen Status hinaus existieren. Kann ich zwar lesen, ist mir aber alles zu anstrengend. Deshalb die beiden Videos, in der Hoffnung etwas erhellendes zu Buckets, Tags, etc. zu finden, ohne die die Chose offenbar nicht läuft.
etwas erhellendes zu Buckets, Tags, etc. zu finden
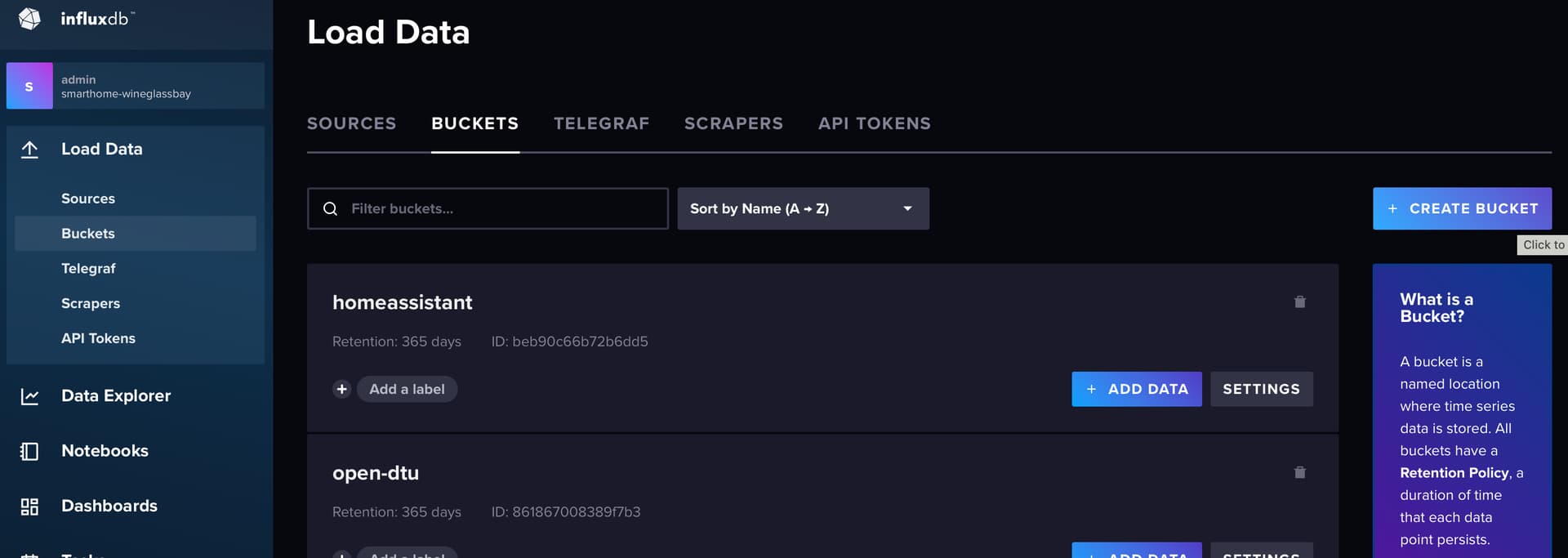
Das Bucket is vergleichbar, mit den sog. Table-Space und mithin ein wenig dem sog. Schema wie bei einer relationalen DB (ich hoffe ggf. anwesende DBAs verziehen mir den Vergleich…) Das Bucket musst Du in Influx erst mal anlegen.
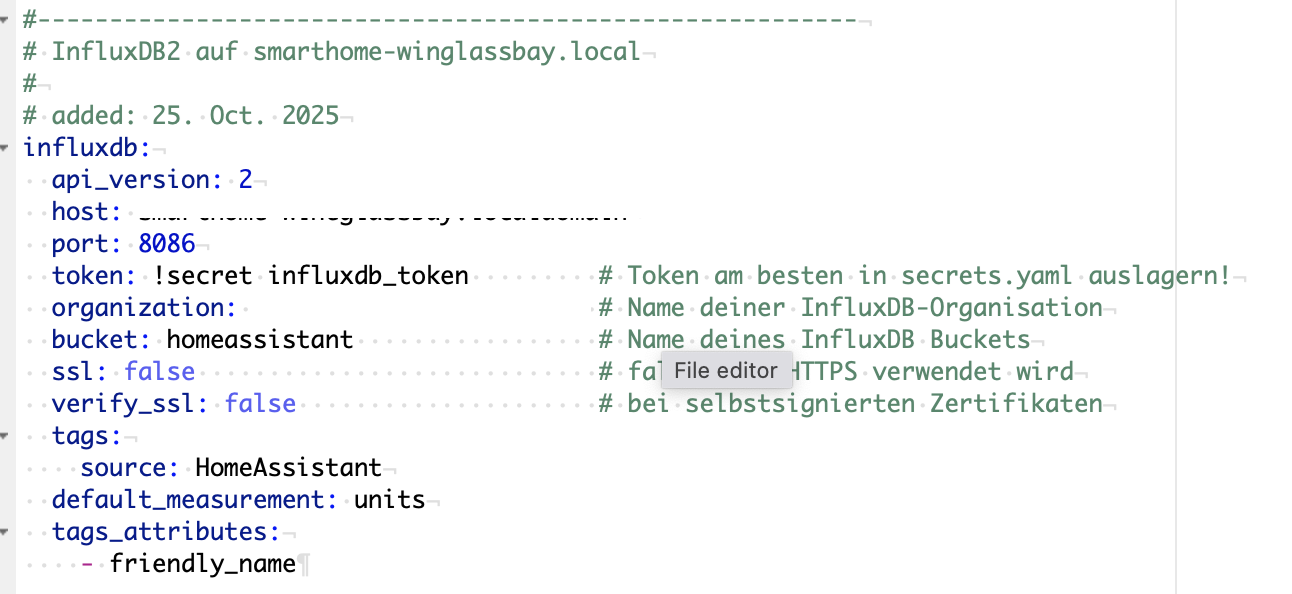
organization und bucket muss Du in der YAML hinterlegen. token habe ich nur eins in Influx generiert. Mit dieser Konfiguration geht jeder Sensor an Influx. Das Bucket selber ist auf ein Jahr Retention gestellt. Mehr geht nicht bei der OpenSource-Variante.
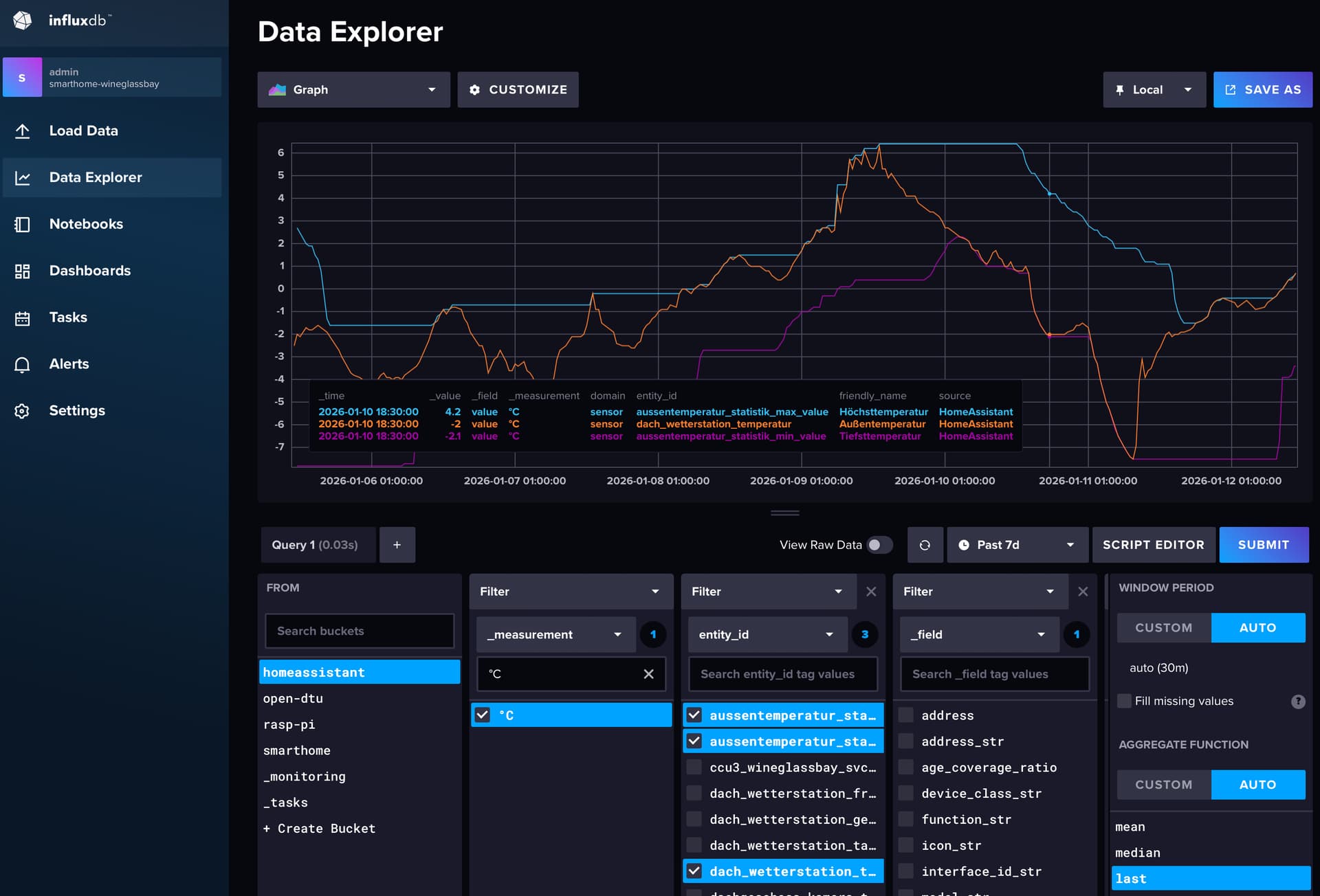
Aber dann steht da was von Tags, Queries und noch so viel. Diese ganze Terminologie überfordert mich gerade. In dem Video von Simon mit der 1er Version kam sowas in der Form überhaupt nicht vor.
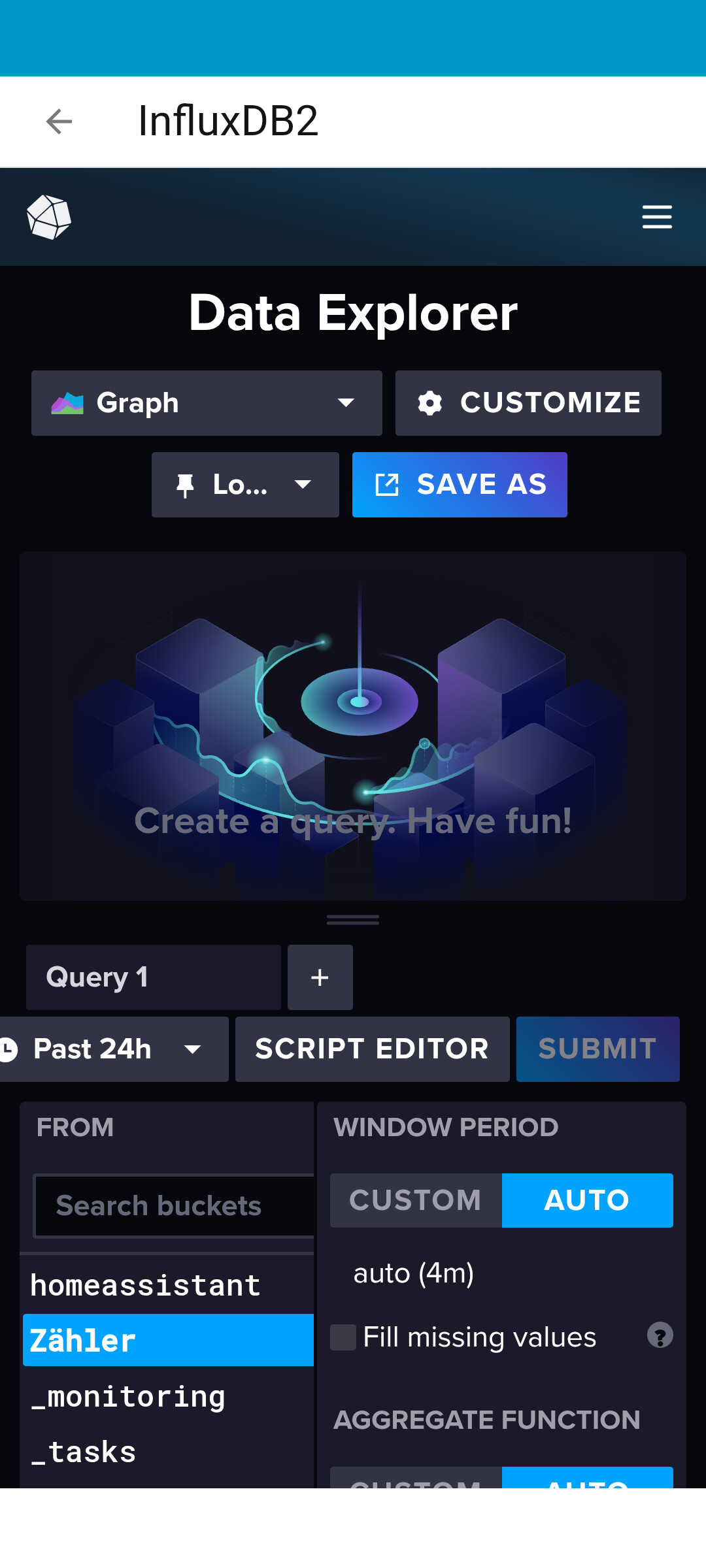
Bezugnehmend auf das Bild: Ist da keine weitereSpalte zwischen dem FROM und WINDOW PERIOD?
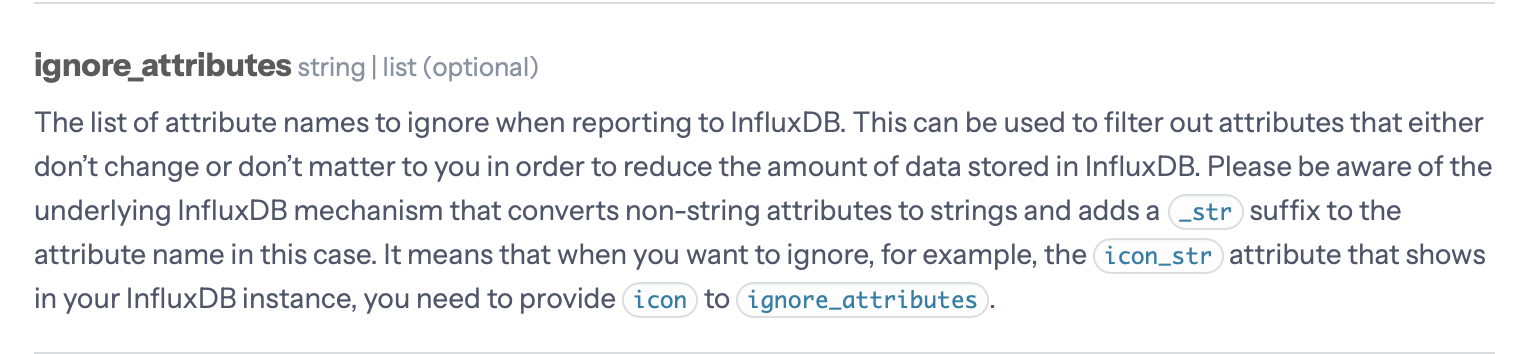
Unter ignore_attributes,hast Du da komplette Liste aus aus dem GitHub-Beispiel stehen? Da ist ja das wichtigste, was Du Reporten willst, ja rausgefiltert!
Entschuldige bitte, aber ich hatte vorhin nur das Handy zur Verfügung. So sieht es am PC aus.
Update: Gerade mal bucket homeassistant angeklickt. Doch, da ist etwas in der nächsten Spalte. Das Ding, welches ich Zähler genannt hatte, wurde nur aus purer Unwissenheit erstellt. Klar, wenn ich jetzt darüber nachdenke ist das auch gar nicht möglich, denn es müsste in der config.yaml “Zähler” statt “homeassistant” stehen. Okay, wie ich sehe, kann ich durch Markierungen jede Menge weitere Filterreihen erzeugen. Ich glaube, es macht gerade klick .
Dann müsste ich nur noch wissen, welche Filter bei meinem Script mit den drei Entitäten am Anfang zu nehmen sind.
Wie ich schon sagte, habe ich es minimal auf meine eigenen Bedürfnisse abgeändert. Diese Entitäten sind mir erstmal die wichtigsten.
Danke für den Tipp und überhaupt für die Beschäftigung mit meinem Thema.
Ich kann jetzt übrigens Werte darstellen, nachdem ich mich mit den Filterlisten im Data Explorer auseinandergesetzt habe. Wahrscheinlich hätte ich das auch schon eher gekonnt, wenn ich auf die Idee gekommen wäre, mal damit zu experimentieren. Aber wie so oft geht man als Anfänger mit dem falschen Denkansatz und Unsicherheit an neue Dinge heran.