Hallo,
nächster Schritt bei mir ist, dass ich alle Daten in HA in eine InfluxDB speichere.
Wenn ich es richte verstanden habe wird durch das Aden die Datenbank direkt in die HA installiert was ich nicht möchte.
Ich werde einen separaten Container erstellen und dort die InfluxDB2 installieren. Wie verbinde ich nun HA mit der InfluxDB korrekt ohne was auf der VM HA zu installieren ?
Hab da bisher in der Doku nichts gefunden
1 „Gefällt mir“
Ich habe das wie folgt gemacht
influxDB 2.x unter Proxmox in eine LXC installiert.
Dort alles konfiguriert.
Dann in der configuration.yaml folgenden Code eingefügt.
influxdb: !include influxdb.yaml #27.04.2023 aktiviert
dann eine Datei influxdb.yaml angelegt und Ort folgenden Code eingefügt
#Config für die influxDB
api_version: 2
ssl: false
host: !secret influxdb_ipaddress #Deine IP-Adresse zur influxDB
port: 8086 #Deine Port zur influxDB
token: !secret influxdb_token #Deine Token zur influxDB
organization: !secret influxdb_organization #Deine Organization zur influxDB
bucket: homeassistant #Deine bucket zur influxDB
tags:
source: HA
tags_attributes:
- friendly_name
default_measurement: units
include: !include influxdb_include.yaml
alles unterhalb von tags: ist dann bereits Konfiguration der influxDB für HA.
Ich habe mich dafür entschieden sämtliche Sensoren, die ich in der influxDB haben möchte explizit zu benennen. Darum die Zeile include: !include influxdb_include.yaml, die wiederum auf eine neue yaml-Datei verweist in der sich alle meine Sensoren befinden. Die Datei sieht in Auszügen wie folgt aus.
entities:
- input_number.korrekturwertsolarproduktion
- input_number.strompreis_in_cent_kwh
- input_number.strompreiseinspeisung_in_cent_kwh
- sensor.ahoy_p_ac
- sensor.ahoy_p_ac_total
- sensor.ahoy_p_dc
- sensor.ahoy_p_dc_1
- sensor.ahoy_p_dc_2
Durch dieses Setup kann ich jederzeit detailliert entscheiden was in die influxDB rein kommt. Ein neuer Sensor oder sonstiges in HA gelangt nicht sofort in die influxDB, sondern erst dann, wenn ich das möchte. So kann und konnte ich in der Vergangenheit in HA auch viel mit Sensoren spielen und musste diese nicht mühsam aus der influxDB wieder löschen.
Viel Erfolg
Claudius
Moin,
steht alles in der offiziellen Dokumentation von Home Assistant.
Siehe InfluxDB - Home Assistant
VG
Bernd
@ryhoruk
Oh das sieht ja gut aus. Danke.
Kurze Frage noch → Hast du die ganzen secrets für die Influx in eine separate Datei geschrieben wo HA sich die Infos rausholt oder dann explizit in die influxdb.yaml ?
@dp20eic
Tja, ich weiss. Für mich als Laie hat es sich nicht erschlossen auf Anhieb, dass hier keinerlei Installation notwendig ist sondern es nur über die yaml geht. Ist halt so … oft werden halt Sachen vorausgesetzt, die zumindest bei mir nicht gleich den AHA Effekt auslösen. Nun hab ich es verstanden, dass lediglich eine Konfiguration in einer yaml Datei notwendig ist.
1 „Gefällt mir“
Ich habe in die secrets.yaml, also eine eigene Datei, alle meine Passwörter und sonstigen Informationen abgelegt, die es erschweren Code zu teilen.
Es ist und war immer umständlicher Code-Schnipsel zu veröffentlichen und dann nochmals alles zu durchsuchen ob eventuell irgendwo was drin steht, was nicht für die Allgemeinheit gedacht ist.
Wenn Du Hilfe zu der secrets.yaml brauchst, dann denke ich wirst du hier im Forum viel dazu finden.
Viel Erfolg
Claudius
P.S. mal ein Screenshot eines Teils meiner Filestruktur. Alte yaml-Dateien hebe ich während aber auch nach einem Umbau immer mal noch eine Weile auf. Diese sind dann mit .old im Namen erweitert.
Moin,
ich meine das ja auch nicht Böse oder, mache da jemanden einen Vorwurf, na vielleicht doch ein bisschen, denn Dokumentation lesen gerät aus der Mode ![]()
Ich halte nicht viel davon fertige Lösungen zu posten, denn nur das selbst erarbeitete bleibt im Gedächtnis, und Jahre später weiß man immer noch, was man da gemacht hat.
Ob Du jetzt die Konfiguration in eine eigene Datei auslagerst, oder ob Du die in die configuration.yaml schreibst, ist Geschmacksfrage, das Ergebnis ist das gleiche ![]()
VG
Bernd
1 „Gefällt mir“
@ryhoruk
Ok Danke. Ich lager auch gerne vieles aus da ich nach x-Monaten eh nicht mehr weiss was ich wohin verfrachtet habe wenn ich vieles einfach so in die configuration.yaml reintue
@dp20eic
Ja ich weiss, ich bin aber jemand der die Doku liest nur oft ist diese so geschrieben, dass viele Dinge vorausgesetzt werden, die ich gar nicht weiss oder kenne. Das ist halt das problem. Aber egal deswegen frage ich ja und habe auch super Hilfe bekommen ![]()
Nachtrag:
@dp20eic & @ryhoruk
Scheint jetzt zu gehen, dass die Daten in der InfluxDB2 landen ! Ich beobachte dies.
Nun aber die Frage wie ich in HA selber mir die Daten dort anzeigen lassen kann ? Oder lasse ich HA auf der 10 Tage Basis so wie es standardmässig läuft und lasse mir dann zB mit Grafana dann den größeren Zeitraum anschauen ? Was ist da empfehlenswert bzw. einzustellen ?
Moin,
das steht auch in der Dokumentation ![]()
Du kannst Sensoren anlegen,
sensor:
- platform: influxdb
api_version: 2
token: GENERATED_AUTH_TOKEN
organization: RANDOM_16_DIGIT_HEX_ID
bucket: BUCKET_NAME
queries_flux:
- range_start: "-1d"
name: "How long have I been here"
query: >
filter(fn: (r) => r._domain == "person" and r._entity_id == "me" and r._value != "{{ states('person.me') }}")
|> map(fn: (r) => ({ _value: r._time }))
value_template: "{{ relative_time(strptime(value, '%Y-%m-%d %H:%M:%S %Z')) }}"
- range_start: "-1d"
name: "Cost of my house today across all power sensor"
query: >
filter(fn: (r) => r.domain == "sensor" and r._field == "value" and regexp.matchRegexpString(r: /_power$/, v: r.entity_id))
|> keep(columns: ["_value", "_time"])
|> sort(columns: ["_time"], desc: false)
|> integral(unit: 5s, column: "_value")
imports: regexp
value_template: "{{ value|float / 24.0 / 1000.0 * states('sensor.current_cost_per_kwh')|float }}"
- range_start: "-1d"
bucket: Glances Bucket
name: "Average CPU temp today"
query: "filter(fn: (r) => r._field == \"value\" and r.entity_id == \"glances_cpu_temperature\")"
group_function: mean
hab ich noch nicht gemacht, da ich Grafana als Dashboard benutze, dazu gibt es aber auch Dokumentation ![]()
VG
Bernd
P.S.: hier einmal eine Seite mit vielen Beispielen, was in Grafana möglich ist ⇒ Grafana
ich habe die mariaDB auf 30Tage stehen.
Außer dem EnergieDashboad interessiert mich in HA nichts wirklich länger. Könnte auch wieder auf den Standard zurück gehen.
Moin,
mit der Aufbewahrungsfrist stehe ich, aktuell noch auf dem Kriegsfuß, was HA angeht, ich mache das mit Tasks, Stichwort Down samplen, in influxDB, Daten, die mir wichtig sind, schreibe ich in ein anderes Bucket, welches dann eine andere Aufbewahrungszeit hat.
Das kann ich dann auch kombinieren, wenn in einem Dashboard Daten aus den letzten Tagen und von vor Monaten vergleichen will, das, was dann älter ist, hat dann halt nicht mehr die Auflösung.
VG
Bernd
War klar ![]() sensor konfigurieren um anstatt die hauseigene DB anzeigen zu lassen auf die Influx ? Na da wäre ich jetzt nicht drauf gekommen
sensor konfigurieren um anstatt die hauseigene DB anzeigen zu lassen auf die Influx ? Na da wäre ich jetzt nicht drauf gekommen
Die Beschreibung dazu erschliesst sich mir aber nicht.
Was ist damit gemeint:
- You must configure the
influxdbhistory integration in order to createinfluxdbsensors. - This can be used to present statistics as Home Assistant sensors, if used with the
influxdbhistory integration.
Okay, also hast du die auf 30 Tage hochgeschraubt ? Ich frage mich ob es nicht besser wäre sich die in HA anzeigen zu lassen also die Influx…oder macht man das nicht ?
Moin,
Du kannst doch auf fast allen Entitäten Dir die Werte der letzten Wochen/Monate usw. anzeigen lassen.
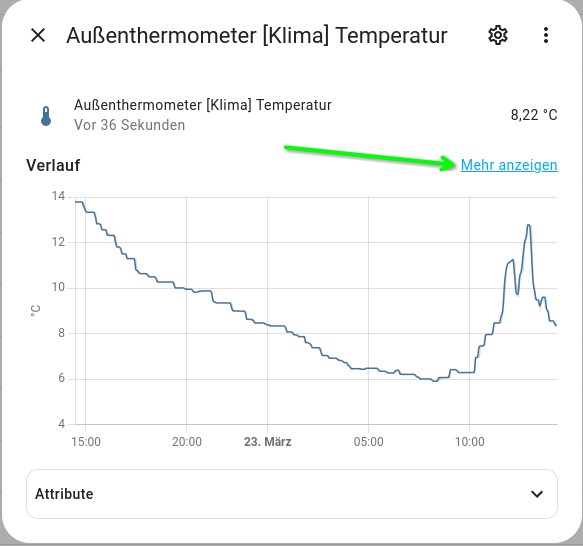
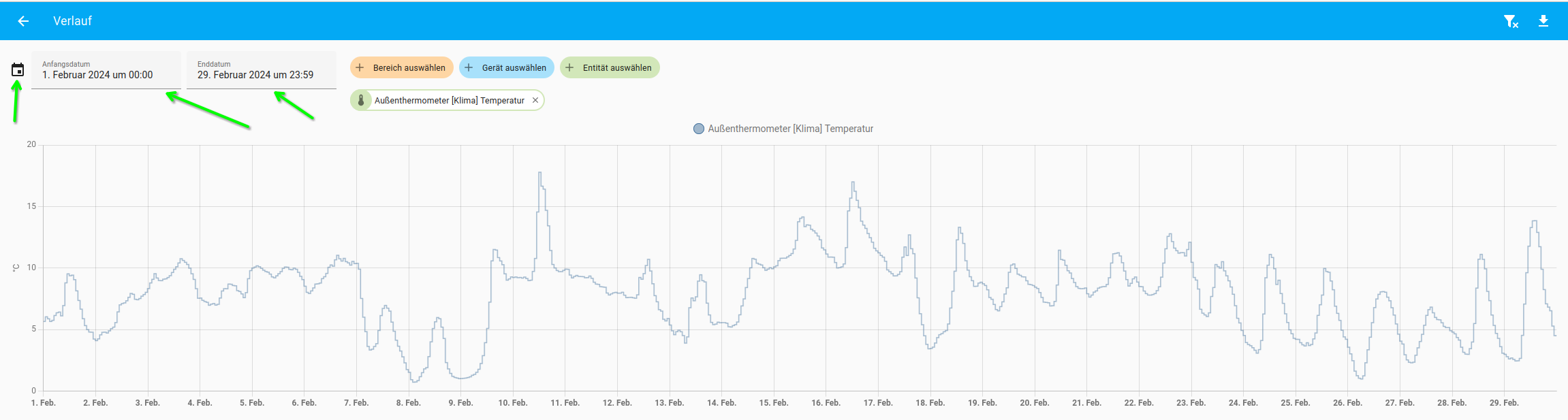
Das kann man dann sicherlich auch in den Kacheln des Dashboards nutzen.
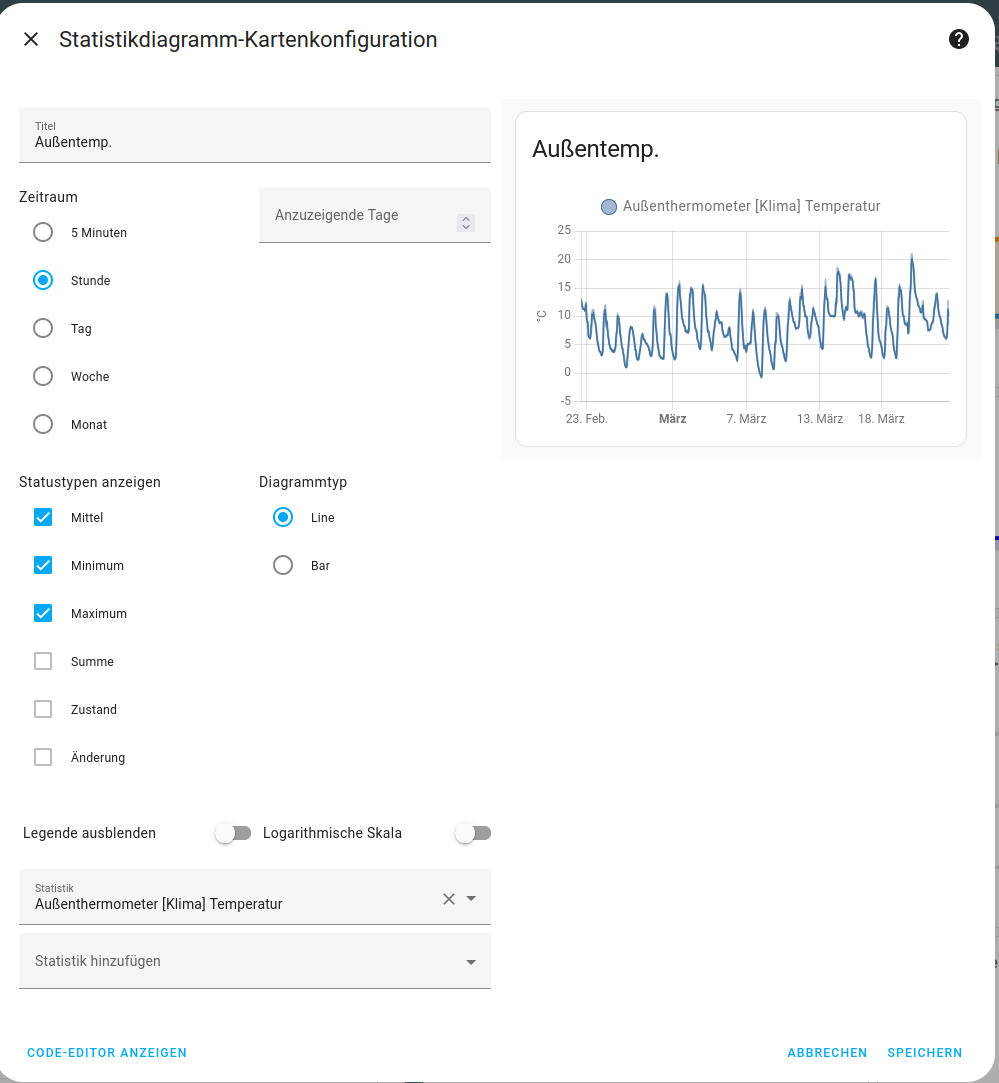
VG
Bernd
P.S.: vielleicht verstehe ich Dich aber auch einfach nicht ![]()
Ich finde die Möglichkeiten graphischer Darstellungen und Auswertungen in HA nicht so überzeugend und performant und nutze deswegen, auch wenn meine Auswertungen in grafana eher einfach sind, lieber grafana.
Ich lerne aber gerne immer wieder hinzu.
Wie gesagt, die 30Tage, die ich eingestellt habe, sind eventuell vollkommen unnötig. Da momentan dafür aber nur 4-6GB benötigt werden tut es mir nicht wirklich weh.
Wie machst du das mit dem verdichteten Ablegen in einem anderen bucket?
Wie stellst du sicher, dass bereits ermittelte Werte nicht nicht durch falsche überschrieben werden?
Bisher habe ich mich da nicht ran getraut. ![]()
Moin,
das ist eine Technik von influxDB, bin gerade dabei nach einem Kernel update, den Proxmox Server wieder zu starten, wenn alles wieder oben ist, dann kann ich da mal zeigen wie das mit Task geht.
VG
Bernd
Mag sein das wir aneinander vorbei sprechen.
Das gezeigte von dir (screenshots) kenne ich ja. das zeigt mir ja im Standard nur die 10 Tage an die in HA sind. Da soll bitte schön dann alles aus der Influx gelesen werden und nix mehr von der lokalen. Wie ich das einstelle habe nullkommanull nach zehnmaligen Lesen verstanden
Moin,
nein, mit irgendeiner Version von HA, wurde das ja geändert, das, was passiert ist, dass die Daten, je älter sie werden, werden sie ungenauer, da die Daten aggregiert werden, siehe dieses Bild, das sind die Werte aus dem Februar
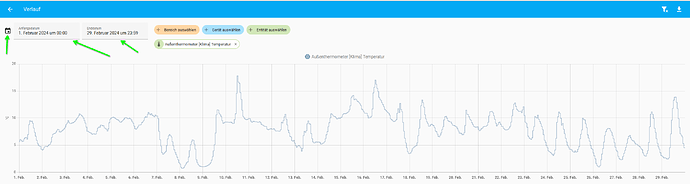
Und nun einmal eine Darstellung aus diesem Monat, wobei Rot, dann etwas reduzierte Werte sind und Blau halt nicht
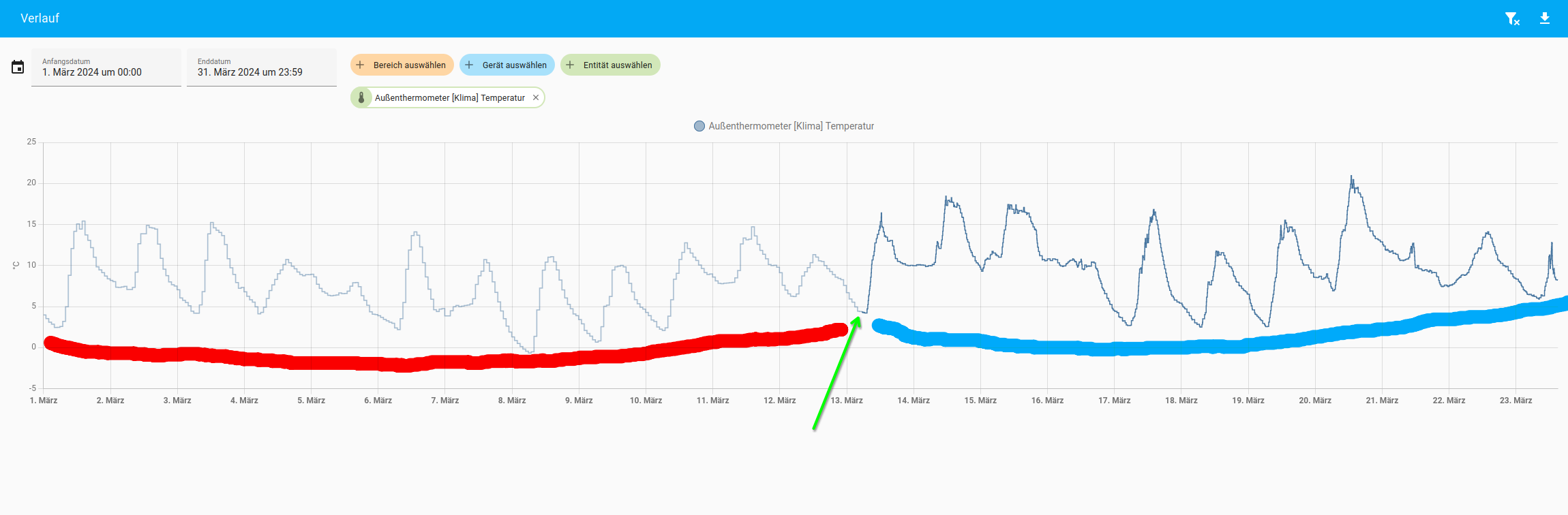
So wird das dann auch in den Kacheln sein, glaube ich ![]()
Hier noch einmal ein Hinweis aus der Dokumentation:
!Not
The `influxdb` database integration runs parallel to the Home Assistant
database. It does not replace it.
Da hast du dann, nach meiner Meinung, zwei Möglichkeiten
- Du nutzt Grafana und
iFramezum Einbinden der Grafana Panels/Dashboards in HA - Du baust dir Sensoren, mit der Abfrage des gewünschten Zeitraums, z. B. zeig mir die kWh Tageswerte, der letzten drei Monate.
Das könnte eine Abfrage sein, mit Umrechnung, falls kWh nicht vorhanden
// Diese Abfrage berechnet den kWh-Tageswert der letzten drei Monate
// InfluxDB-Datenquelle auswählen
from(bucket: "meinen_bucket")
// Datumsbereich der letzten drei Monate festlegen
range(start: -3mo, stop: now())
// Die Spalte "Leistung" in kW auswählen
|> filter(fn: (r) => r["_measurement"] == "me Messung")
|> filter(fn: (r) => r["_field"] == "Leistung")
// Werte in kWh umrechnen (Leistung * Zeit)
|> map(fn: (r) => r["_value"] * r["_time"] / 3600000000000)
// Nach Tag aggregieren (Mittelwert der kWh-Werte)
|> group(by: time(r: 1d), fn: mean)
// Ergebnis als Tabelle ausgeben
|> yield(name: "kWh_Tageswert")
Oder/dann, das Ganze in einen Sensor packen
- Erstellen einen Sensor in Home Assistant:
- Gehe in Home Assistant auf “Einstellungen” > “Geräte & Dienste” > “Sensoren”.
- Klicke auf “Gerät hinzufügen”.
- Wähle “Manuelles Gerät hinzufügen”.
- Gebe einen Namen für den Sensor ein, z. B. “kWh_Tageswert”.
- Wähle “InfluxDB” als Gerätetyp.
- Wähle die zuvor erstellte InfluxDB-Integration aus.
- Füge folgende YAML-Konfiguration in das Feld “Konfiguration” ein:
type: influxdb_v2
query: """
from(bucket: "meinen_bucket")
range(start: -3mo, stop: now())
|> filter(fn: (r) => r["_measurement"] == "me Messung")
|> filter(fn: (r) => r["_field"] == "Leistung")
|> map(fn: (r) => r["_value"] * r["_time"] / 3600000000000)
|> group(by: time(r: 1d), fn: mean)
|> yield(name: "kWh_Tageswert")
"""
unit_of_measurement: "kWh"
Anschließend sollte der Sensor in Home Assistant angezeigt werden und den kWh-Tageswert der letzten drei Monate anzeigen.
Alles nur Theorie, ob das Klappt habe ich nicht getestet, kann auch sein, dass da totaler Bullshit herauskommt ![]()
VG
Bernd
Mhhh,
wenn ich das alles so lese, dann kann ich immer nur für EINEN Sensor was einstellen, also zB gib mir die letzten 3 Monate. Wenn ich aber nur mal 2 oder 1,5 haben möchte geht das bei HA gar nicht ? Wenn das so ist macht das alles keinen Sinn und ich kann nur über Grafana gehen.
Allerdings hatte ich mir das ein wenig anders vorgestellt … aber gut ich lerne ja dazu ![]()
Moin,
Achtung ist ein Beispiel für Version 2, also in influxDB, einen Task erstellen, wenn dazu fragen sind, wie das geht, hier fragen oder Dokumentation lesen ![]()
So könnte eine Abfrage aussehen
// Diese Task führt ein Downsampling der Messwerte durch
// InfluxDB-Datenquelle auswählen
from(bucket: "meinen_bucket")
// Datumsbereich festlegen
range(start: -1y, stop: now())
// Die Spalte "Leistung" in kW auswählen
|> filter(fn: (r) => r["_measurement"] == "me Messung")
|> filter(fn: (r) => r["_field"] == "Leistung")
// Werte in kWh umrechnen (Leistung * Zeit)
|> map(fn: (r) => r["_value"] * r["_time"] / 3600000000000)
// Nach Stunde aggregieren (Mittelwert der kWh-Werte)
|> group(by: time(r: 1h), fn: mean)
// In neuen Bucket "downsampled_data" schreiben
to(bucket: "downsampled_data")
// Task alle 10 Minuten ausführen
every(10m)
Erklärung des Task:
from(bucket: "meinen_bucket"): Wählt die InfluxDB-Datenquelle mit dem Namen meinen_bucket" aus.range(start: -1y, stop: now()): Legt den Datumsbereich auf das letzte Jahr fest.filter(fn: (r) => r["_measurement"] == "me Messung"): Filtert die Daten nach der Messung mit dem Namen “me Messung”.filter(fn: (r) => r["_field"] == "Leistung"): Filtert die Daten nach der Spalte “Leistung”.map(fn: (r) => r["_value"] * r["_time"] / 3600000000000): Rechnet die Leistung in kWh um (Leistung * Zeit in Sekunden / 3600000000000 (Faktor für Umrechnung von Sekunden in Stunden und kW in kWh)).group(by: time(r: 1h), fn: mean): Gruppiert die Daten nach Stunde und berechnet den Mittelwert der kWh-Werte.to(bucket: "downsampled_data"): Schreibt die aggregierten Daten in den neuen Bucket “downsampled_data”.every(10m): Führt den Task alle 10 Minuten aus.
So und dann ist es ja so, dass influxDb schlau genug ist, um zu erkennen, ob sich ein Wert geändert hat oder ob er gleich ist, und trägt gleiche Werte nicht noch einmal ein.
Die neuen Werte werden auch in einem anderen Bucket gespeichert, das original Bucket bleibt unberührt.
Du kannst ja den Zeitraum für die Abfrage der Werte anpassen, sagen wir mal dein Bucket A stellt die Werte für 30 Tage zur Verfügung, dann kann man die Range auch so eingrenzen
`range(start: -29d, stop: -1d`: Legt den Datumsbereich auf, vor 29 Tagen, bis gestern.
Da es ja schon historisierte Daten sind, sollten die sich ja nicht mehr änder
Wenn du das dann einmal Täglich ausführst, dann kommen nach dem ersten Lauf, nur noch Daten ins neue Bucket, die -1 Tag alt sind, da die anderen 28 ja schon übertragen worden.
So, bei den letzten Sätzen, bin ich mir nicht klar, ob das verständlich ist ![]()
VG
Bernd
1 „Gefällt mir“
Moin,
um ehrlich zu sein, kann ich Dir gerade nicht folgen.
Mach das doch mal an einem konkreten Beispiel fest.
VG
Bernd
1 „Gefällt mir“