Moin!
Ausnahmsweise mal kein “Ich hätte da gerne mal ein Problem”-Posting. Auslöser war ein Problem, aber ich dachte, es könnte anderen helfen, die Lösung hier zu dokumentieren ![]()
Problem war: Mein Zigbee-Controller hat sich nach dem Hinzufügen von einigen (in Summe 15) SONOFF S60ZBTPF mindestens einmal am Tag “festgefressen” (“BUFFER_FULL”-Fehler) und war nur durch ein Restart des Zigbee2MQTT-Addins in HA wieder zu reanimieren. Da ich auch die Garten-Bewässerung über Zigbee-Geräte (ein paar Sonoff SWV-ZFE) steuere, war das natürlich vor der beginnenden Urlaubszeit jetzt echt ein Problem…
Mein erster Verdacht war, daß mit >100 Devices im Mesh dann doch irgendwo die Grenzen des verwendeten SONOFF ZBDongle-P-Klons erreicht wären. Also begann ich, mich mit dem Gedanken anzufreunden, tagelang durchs Haus zu laufen um die Geräte für den Wechsel auf einen anderen, leistungsfähigeren Coordinator neu anzulernen.
Dabei ist mir dann aber noch eine andere Idee gekommen, die dann tatsächlich - Stand jetzt - das Problem auch ohne Coordinator-Wechsel gelöst hat: “Reporting-Einstellungen” ist das Zauberwort.
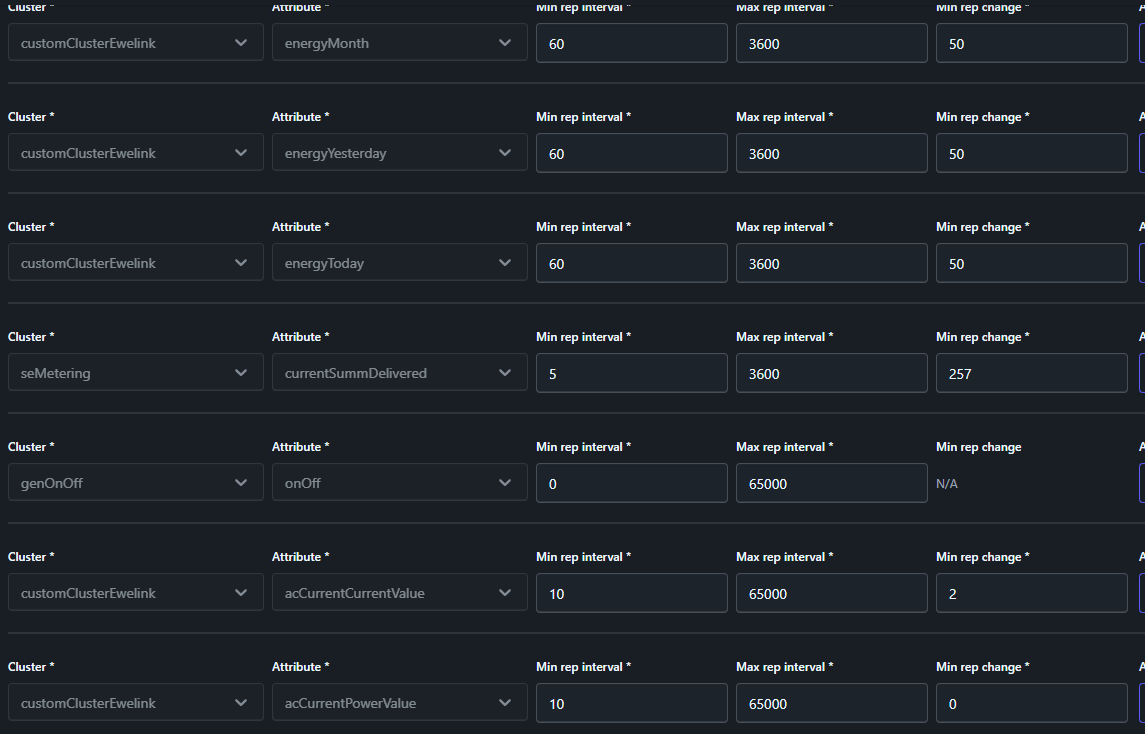
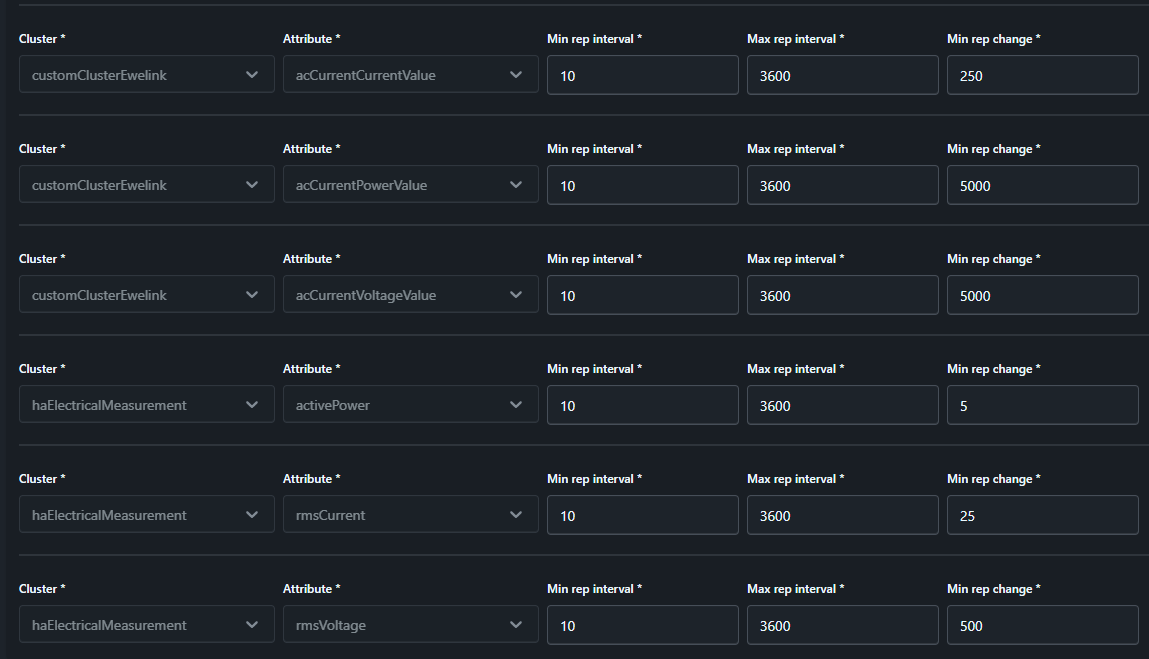
So wie es aussieht, entsprechen die in Z2M angezeigten Default-Reporting-Einstellungen an den S60ZBTPF nicht ganz der Realität. So werden für die SONOFF- bzw. Ewelink-spezifischen customClusterEwelink-Attribute ‘acCurrentVoltageValue’, ‘acCurrentCurrentValue’ und ‘acCurrentPowerValue’ z.B. ein ‘Min rep interval’ von 60 angezeigt, was aber nicht stimmen kann wenn ich mir das Log in Z2M anschaue und sehe, das die Dinger permanent die kleinsten Schwankungen reporten.
Das führt dann auch zum nächsten Punkt: Diese 3 Werte werden in Tausendstel(!) gemessen, d.h. mW, mA und mV - was natürlich hochgradiger Blödsinn ist für Messung im Niederspannungs-Bereich. Zusammen mit dem offensichtlich im Default nicht funktionierenden Reporting-Intervall und den standardmäßig lächerlich niedrig eingestellten “Min rep change”-Schwellwerten zu _extrem_ geschwätzigem Reporting-Verhalten führt.
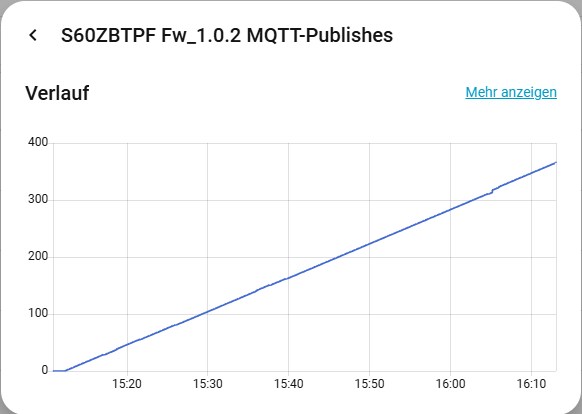
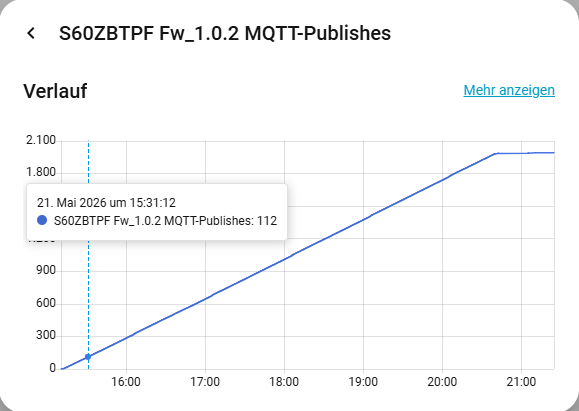
Ich hab’ dann mal eine kleine Messreihe aufgesetzt und gemessen, wieviel MQTT-Publishes denn so eine S60ZBTPF pro Zeiteinheit mit den Default-Einstellungen produziert - und das waren 0.2 - 0.4 pro Sekunde. Das ganze mit 15 multipliziert und mit Einrechnungen der restlichen (Router-)Geräte (div. IKEA Inspelning, Nous L6Z und B2Z) ergab das dann schon ordentlich “Grundrauschen” im Mesh.
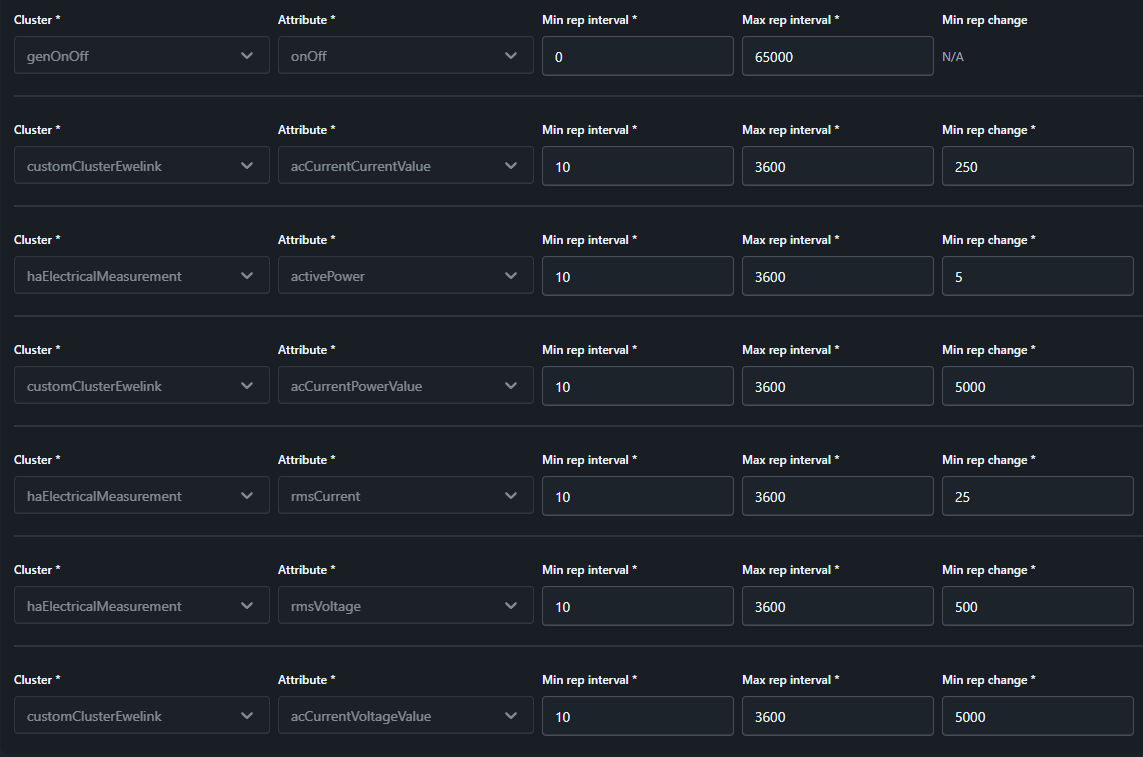
Basierend auf dieser Messung habe ich dann das Reporting-Intervall für die drei o.g. Messungen mal explizit auf 10 Sekunden und die Schwellwerte auf 250 / 5000 / 5000 (0.25 A / 5 V / 5 W) gesetzt und beobachtet. Die Publish-Rate ging recht bald auf deutlich gesündere Werte von ca. 0.02 / s runter.
Zur Sicherheit habe ich dann noch für activePower, rmsCurrent und rmsVoltage analog das Intervall und die Reporting-Schwellen angepasst (Achtung: hier sind rmsCurrent und rmsVoltage in 100stel A bzw. V und activePower in “ganzen” W skaliert).
Mit den o.g. Änderungen an allen S60ZBTPF läuft das Mesh jetzt seit einigen Tage sehr stabil und auch deutlich “responsiver” als vorher - was nicht weiter verwundert, wenn die Kommunikations-Wege nicht permanent durch Blödsinns-Reporting verstopft werden.
Vielleicht hilft das obige auch anderen, die vor ähnlichen Problemen stehen ![]()
Gruß,
Marc