Hallo zusammen,
ich möchte gerne die Daten aus der App/Webseite stundenpan24vertretungsplan von Indiware in den HA integrieren - entweder als Integration oder als Import der Daten.
Danke für die schnelle Antwort.
Ja, das geht in die richtige Richtung.
Meine Idee war, mir den Weg, die Website selber auszulesen zu sparen
vor allem, da relativ schwierig abzugreifen (Benutzername, Passwort, Schulnummer, Klasse etc.)
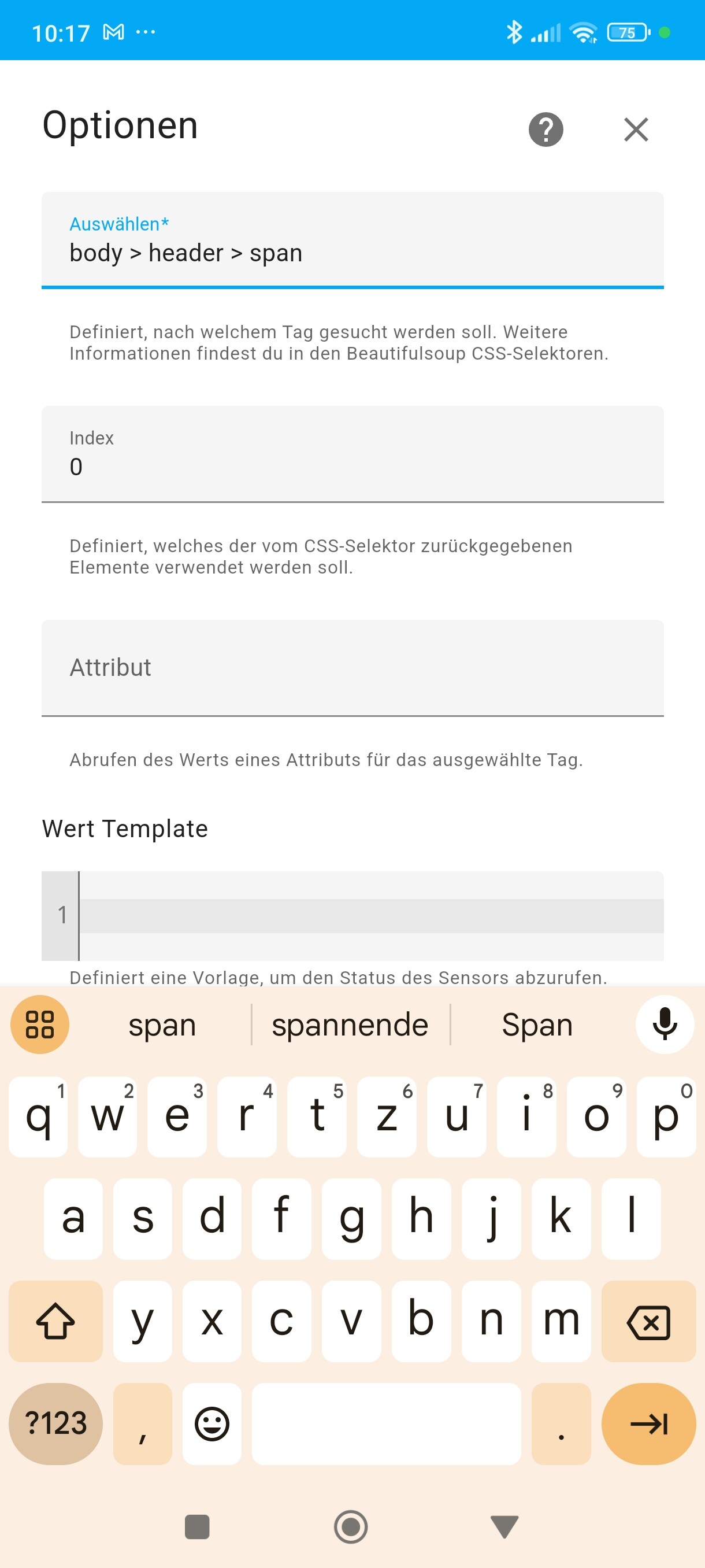
ich habe im 1. Anlauf die “Datenquelle” auf der Seite auch nicht so richtig finden können (Stichwort: Selektor) - liegt aber wahrscheinlich an mir
Stattdessen wollte ich auf eine der beiden OpenSource Quellen zuzugreifen, die ja die Daten bereits strukturiert zur Verfügung stellen!? Oder bin ich da völlig auf dem falschen Weg?
Spannend, ich steh gerade vor einer ähnlichen Idee. Ich würde gern auf den Notenspiegel meines Sohnes zugreifen, der auf beste.schule vorliegt. Auch hier gibt es eine API, nur steig ich noch nicht ganz dahinter, wie ich die Daten in HA bekomme.
@harryp : Das Video habe ich in diesem Zusammenhang auch gesehen. Leider bringt es mich nicht weiter, da ich immer am Login scheitere.
Das sieht nach einer guten Erklärung aus. Werde ich mal probieren.
Update:
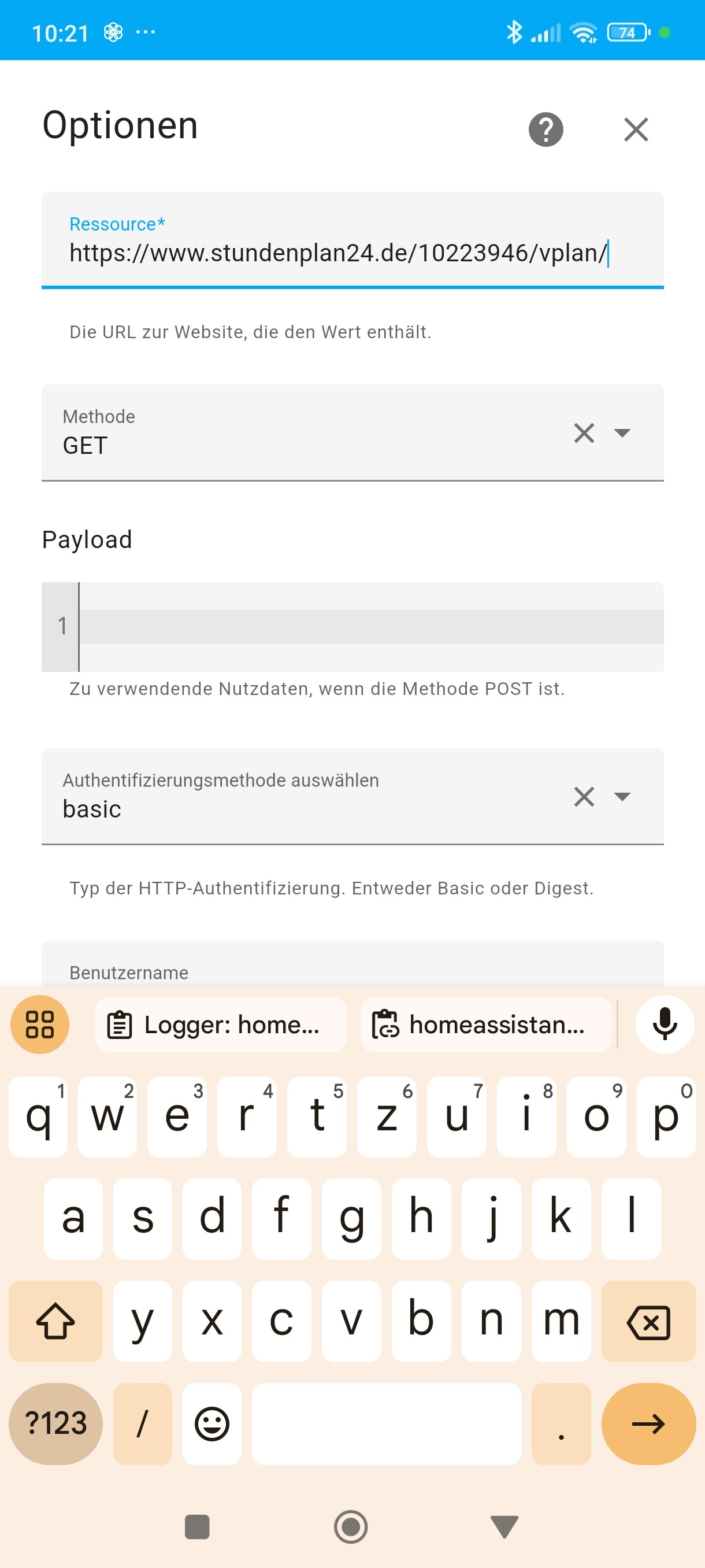
Also, mit dem Scraper funktioniert der Zugriff, auch die Zugangsdaten funktionieren und einen einfachen Text habe ich auch herausziehen können.
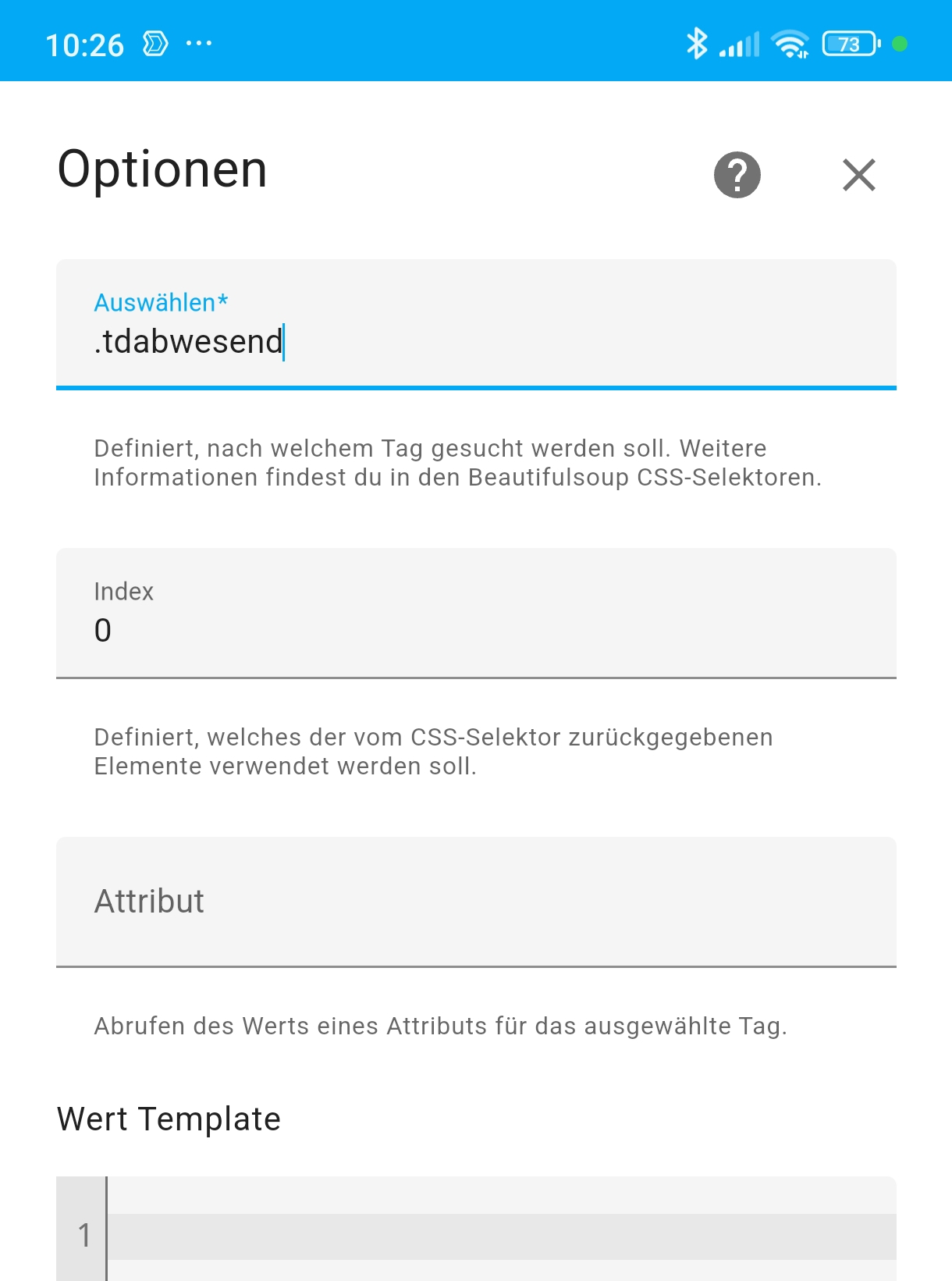
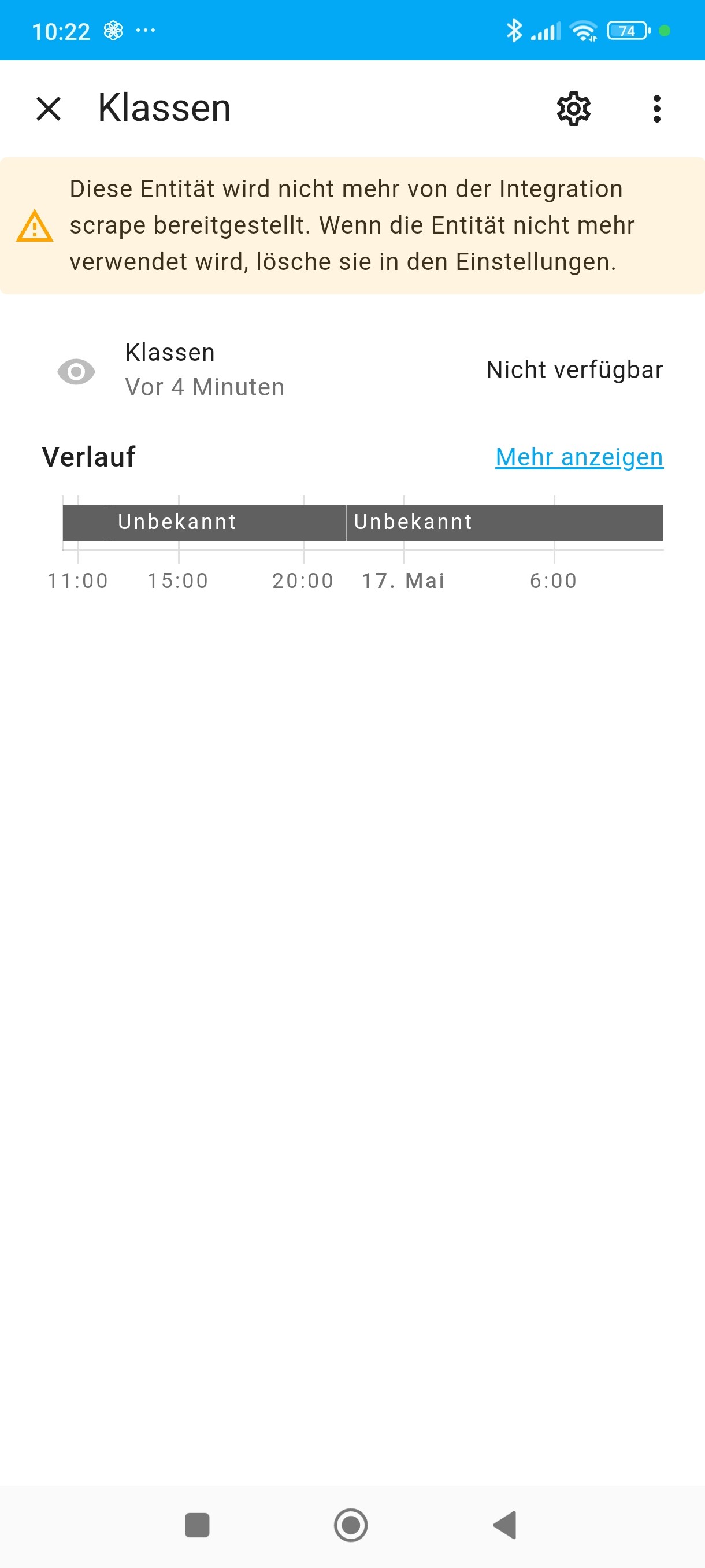
Allerdings gelingt es mir nicht, die relevanten Daten zu scrapen.
Sind diese Daten “nur” eingebettet? (Sorry für meinen laienhaften Ausdruck)
Ich bin kein Datenschutzbeauftragter, aber Du zeigst im Bild Daten, die ich für nicht korrekt halte, denn dort stehen Namen, ich würde das Bild löschen oder den Bereich unkenntlich machen.
Wieso, wenn Du das, was da Hellblau hinterlegt ist, Scrapen willst, dann ist das doch
Danke für den Tipp.
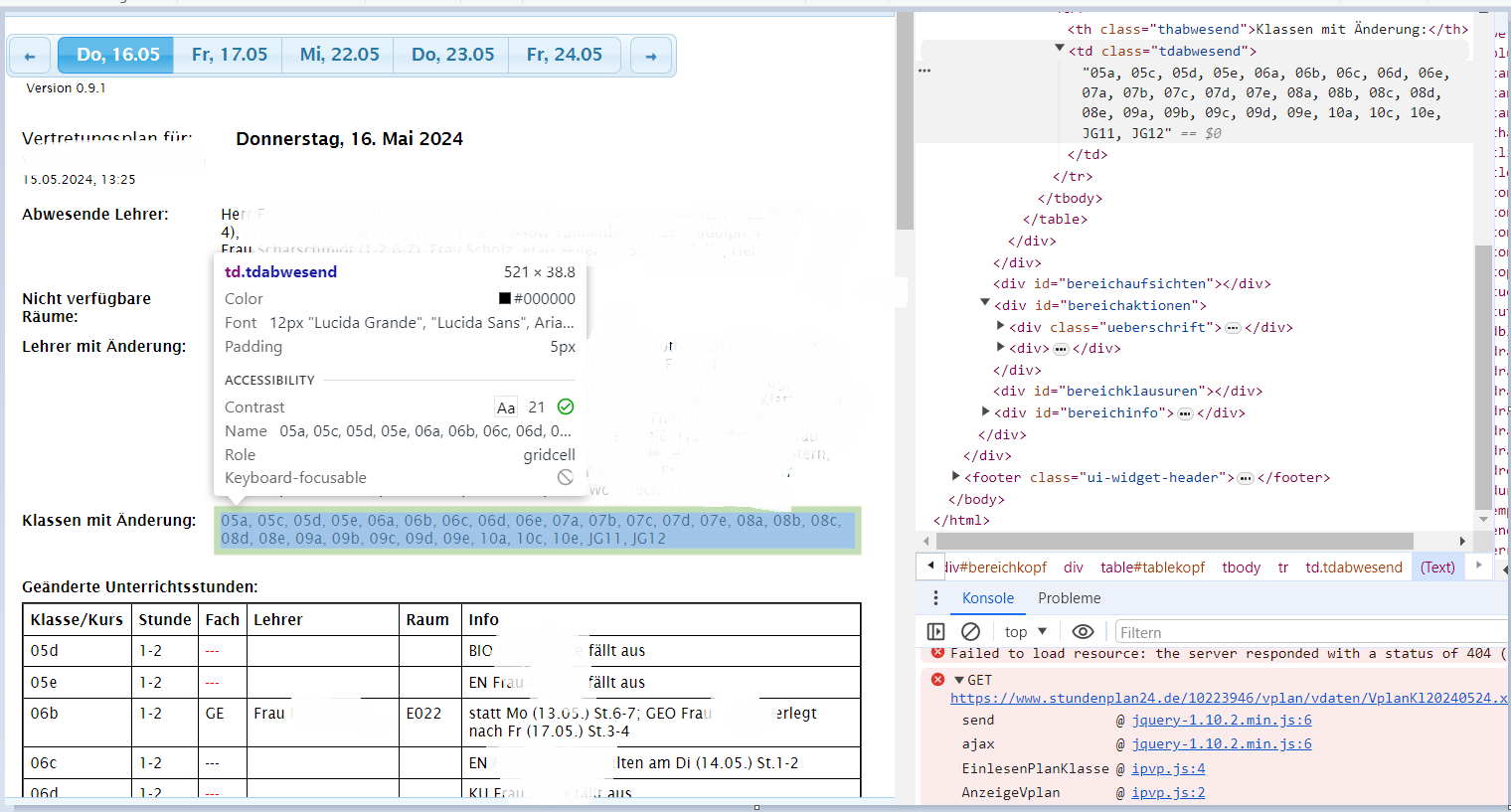
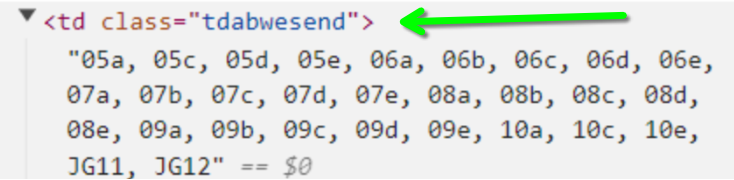
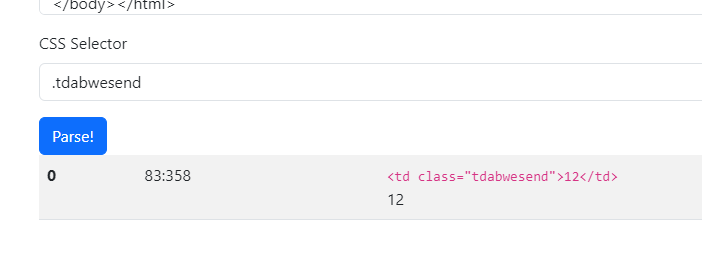
Im 1. Schritt liefert auch .tdabwesend ein unbekannt zurück.
Ich werde heute abend nochmal in Ruhe über den Link von dir testen.
Danke!
Update: Komme leider nicht vorwärts.
Ich vermute, dass im Hintergund xml Daten gelesen werden und als Tabelle eingebettet werden.
Ich verlinke hier mal die Testschule: Vertretungsplan online
Im ersten Schritt möchte ich die Klasse mit Änderung auslesen.
Hat schon jemand hinbekommen von der Ecowitt Webseite die öffentlich zur verfügen gestellten Stationen zu scrapen? Gibt es da einen Trick? Ist die Seite dynamisch und deswegen bekomme ich es nicht hin?
Das ist auch so. Für die Beispielschule sieht das so aus. Überden Link kommt man auf eine xml für den Vertretungsplan.
Mit “VplanKl.xml” scheint man immer den aktuellen Plan des Tages zu bekommen. Man kann aber auch ein spezielles Datum abfragen. Da sieht die aufzurufende Datei dann so aus: VplanKl20240815.xml. Fand ich in dieser PDF von Indiware.
Für die Beispielschule ist das auch nicht schwierig, an die Daten zu kommen. Allerdings wird bei der Schule meiner Kinder immer erst noch Benutzernamen und Kennwort abgefragt. Ich bin noch nicht dahinter gekommen, wie ich das aus HA heraus machen soll. Alternativ ginge auch NodeRed.
Ja, hier komme ich auch nicht weiter. Meine Vorstellung wäre, dass in der xml gesucht wird, ob die Klasse, in die meine Tochter geht (hier z.B. Kl. 7c) vom Vertretungsplan betroffen ist (also, ob es Änderungen zum normalen Stundenplan gibt).
Wenn der Wert “7c” in der Datei nicht gefunden wird , erledigt. Wenn der Wert “7c” irgendwo auftaucht, soll eine Benachrichtigung erstellt werden (Achtung Stundenplanänderung) oder ein Sensor einen bestimmten Wert erhalten (z.B. Änderungen: ja)
Mit NodeRed habe ich das hinbekommen, allerdings noch nicht vorzeigbar, da experimentell.
Außerdem habe ich festgestellt, dass es gar nicht so schwer ist, Benutzernamen und Kennwort zu übergeben. Im Browser funktioniert das ganz einfach mit folgendem Link:
Allerdings würde ich das so nicht tun, da Nutzer und Kennwort im Klartext übermittelt werden.
Man kann damit auch gezielt ein Datum abfragen. Dann einfach den Dateinamen ergänzen, z. B:
VplanKl20240827.xml
In NodeRed funktioniert der Abruf per HTTP Request-Node. Dann die erhaltene xml in eine json umwandeln und auswerten. Da bin ich aber noch am testen, da es so viele Daten sind, die da mitkommen. Und ich bin auch nicht der Profi für sowas, sondern mache das meiste mit probieren und ChatGPT.
Ok, ich bin nun soweit, dass ich mir die Anzahl der Änderungen für die kommenden zwei Schultage (mehr ist natürlich möglich) anzeigen lasse. Dabei wird auch das Wochenende berücksichtigt.
Das Auslesen der Daten habe ich über NodeRed gelöst, weil das für mich logischer zu gestalten ist. Sicher kann man das aber auch als Rest-Sensor in der yaml machen.
Welche Veränderungen es im Stundenplan gibt, erfasse ich auch. Da brauche ich aber noch etwas, um das sinnvoll darzustellen, da die Struktur der Daten recht unübersichtlich ist. Ist für mich auch nicht so dringend, da ich es besser fände, wenn man den Stundenplan insgesamt anzeigen könnte, also reguläre Stunden + Veränderungen.
.
EDIT: Habe gerade gefunden, dass es doch Daten gibt, bei denen man Änderungen und aktuellen Plan gemeinsam hat. Zu finden ist das unter dem Link