Ich spiele gerade ein bisschen mit dem Assist rum und zwar die local variante mit Piper/Whisper. Grundlegend funktioniert es, auch wenn ich mir vorkomme als quatsche ich ein Anrufbeantworter voll.
Ich hab die verschiedenen Modelle mal duchgetestet und festgestellt das das kleinste für RP4 etc. nur böhmische Dörfer versteht. Dafür reagiert es … naja … relativ schnell. Obwohl ich schneller zu jedem Lichtschalter gelaufen wäre.
Small-int8 ist da schon besser aber viel träger und der Celeron vom Nuc an der Kotzgrenze.
Da musste ich schmunzeln wenn einer nach Hatdwareempfehlungen fragt und ein NUC 11 total oversized ist
Nun, fürs Sprachmodell brauchts wohl doch Macht unter der Haube plus Nitro.
Hat jemand mal mit dem Zeugs gespielt und kann seine Erfahrungen kundtun? Und welche Hardware dafür genutzt wurde?
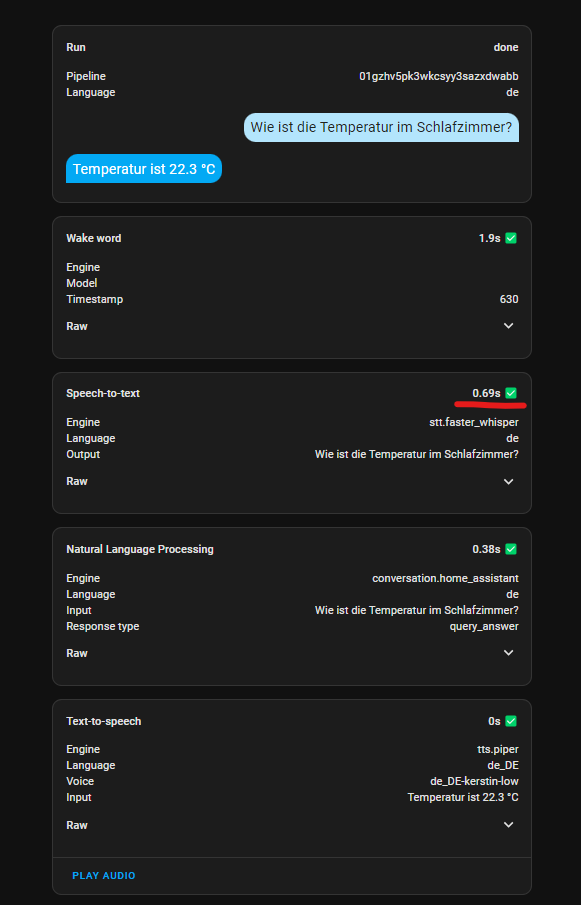
Was ich nicht hinbekommen habe, eine Antwort zu bekommen wie warm es im Wohnzimmer ist. Entweder meint er keine scene oder keine climate zu finden. Das Thermometer wird einfach ignoriert trotz allermöglichen Aliase.
In China hat meine S3-Box nur ca. 50€ gekostet. Klappt eigentlich ganz gut und vor allem kann man am dieplay lesen, was verstanden wurde, Dann kann man statt “Fluter” noch “Fluta” zusätzlich hinterlegen um die Trefferquote zu erhöhen.
Dellmini hab ich gar nicht wahrgenommen
Ja der wird mehr Bumms haben als ein NUC7 mit Celeron.
Ich versuch es schon lokal zu nutzen, einfach mal schauen wie weit man kommt.
PC DELL OPTIPLEX 7040 MICRO INTEL CORE I5-6600T 4X 2.7GHZ mit 32GB RAM und 1TB SSD
Läuft bei mir mit einer Auslastung von 8%-13% und einer Stromaufnahme von ca. 12W. Habe ich reburbished online für €150 gekauft (konnte ich auf der Seite selber konfigurieren).
War noch Win-Doof 11pro dabei (konnte ich leider nicht abwählen )
Hab mich mal schlau gelesen, Whisper verballert richtig Ressourcen wenn man das Maximum rausholen will, aber auf der GPU. Es gibt einige schöne Experimente im HA-Forum via Docker, Proxmox, mit CuDA etc. Ist auf jeden Fall ein schönes Projekt. Muss ich mal in der Firma rumstöbern, ob ich eins zwei Elitedesk 800 G5 abstauben kann, die haben wir noch zur Genüge rumliegen, muss nur rausfinden wieviele uns gehören und welche geleast waren
Stunden später…
Das Thema mit Whisper hat mich nicht mehr in Ruhe gelassen, und dann hab ich in meinem Kopf rumgegraben und da ist mir eingefallen das ich von meinem Uralt-Lab noch Zeugs da habe und damit werde ich ein Lab mit Proxmox reaktivieren
Da ich 2 Xeons übertrieben finde und das Supermicro Board viel zu gross ist, gehe ich noch eine Generation zurück
ASROCK X99M Extreme 4
4x16Gbyte Kingston DDR4 2133 Server-Memory
einen meiner LGA2011-3 Xeon E5-2620 v3 Prozessoren
NVidia Geforce GTX 1060
kommt noch eine 1TB Corsair NVME PCIe4x4 dran (muss noch geshoppt werden)
und ein Netzteil (muss noch geshoppt werden)
Billiger gehts nicht, schon gar nicht wenn es auf die GPU ankommt.
Hätt nicht gedacht das ich meine teils 10Jahre alte Technik wieder vorhole, aber wie sagt Rocky von PawPatrol? (Grüsse an alle Väter mit kleinen Kindern)
“Nicht verschwenden, wieder verwenden”
2 Tage schrauben, von der Hardware via Proxmox → LXC → Docker und dem ganzen NVidia Wahnsinn, hab ich es geschafft
Ein komplett lokales Sprachmodell schneller als Alexa und Google zusammen
Jetzt muss nur noch am Sprachverständnis gefeilt werden.
Das medium-int8 Model reagiert in unter 1 Sekunde, nur das WakeWord könnte schneller reagieren. Eine Frage kostet ca 60W