Moin,
das ist etwas unverständlich, was Du da machen möchtest, also ich verstehe es nicht 
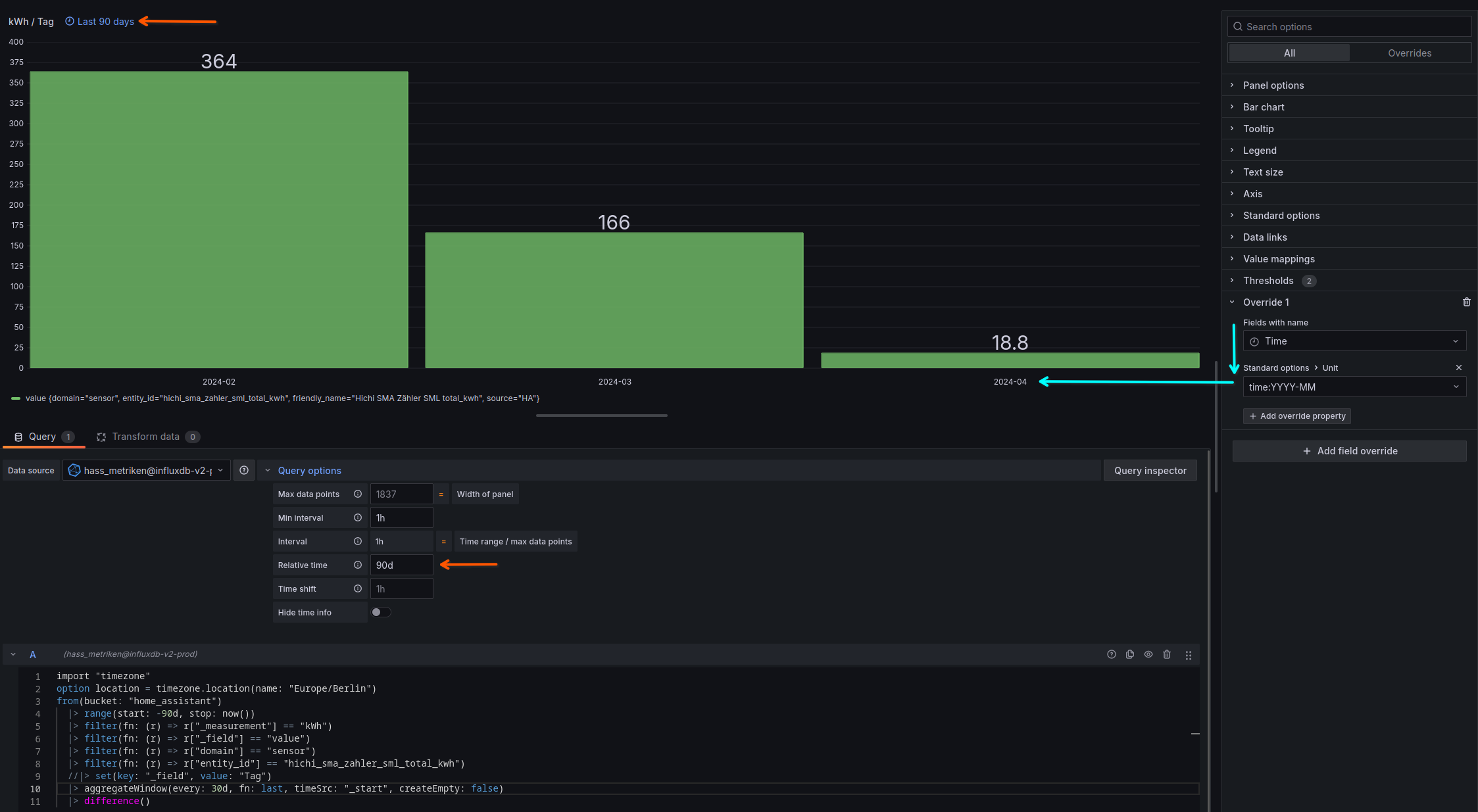
Das Diagramm, welches Du da zeigst, zeigt ja Werte von mehreren Tagen im März an! Wenn Du da Werte vom Monat haben willst, dann musst Du auch den aggregierten Wert des Monats abfragen.
Zeig doch bitte mal die Abfrage, die zu diesen Daten führt.
VG
Bernd
P.S.: Ein Beispiel, ich frage den Stromverbrauch der letzten 90 Tage ab, und aggregiere die Werte zu Monat 30 Tage
Erklärung der InfluxDB FLUX Abfrage
Diese Abfrage holt den Gesamt-kWh-Verbrauch eines Zählers aus Ihrer InfluxDB-Datenbank und aggregiert die Daten zu monatlichen Werten. Schauen wir uns die einzelnen Schritte genauer an:
1. Zeitzone importieren und setzen
Code-Snippetimport "timezone" option location = timezone.location(name: "Europe/Berlin")
import "timezone": Importiert die “timezone” Bibliothek, die Funktionen zur Handhabung von Zeitzonen bereitstellt.option location = timezone.location(name: "Europe/Berlin"): Setzt die Zeitzone für die Abfrage auf “Europe/Berlin”. Dies stellt sicher, dass die Zeitangaben in den Ergebnissen Berliner Zeit entsprechen.
2. Datenquelle und Zeitraum angeben
Code-Snippetfrom(bucket: "home_assistant") |> range(start: -90d, stop: now())
from(bucket: "home_assistant"): Definiert die Datenquelle. Hier wird der Bucket “home_assistant” abgefragt.|> range(start: -90d, stop: now()): Legt den Zeitbereich für die Abfrage fest. -90d bedeutet 90 Tage in der Vergangenheit und now() bezieht sich auf den aktuellen Zeitpunkt.
3. Daten filtern
Die folgenden Filter grenzen die Daten auf spezifische Messungen ein:
filter(fn: (r) => r["_measurement"] == "kWh"): Filtert nach Messungen (“_measurement”) mit dem Namen “kWh”.filter(fn: (r) => r["_field"] == "value"): Filtert nach Feldern (“_field”) mit dem Namen “value”.filter(fn: (r) => r["domain"] == "sensor"): Filtert nach Datenpunkten (“r”) mit dem Domänen-Tag (“domain”) gleich “sensor”.filter(fn: (r) => r["entity_id"] == "hichi_sma_zahler_sml_total_kwh"): Filtert nach Datenpunkten mit der Entity-ID (“entity_id”) “hichi_sma_zahler_sml_total_kwh”. Dies wählt vermutlich den Zähler, dessen Gesamt-kWh-Verbrauch Sie abfragen möchten.
4. Kommentar
Code-Snippet//|> set(key: "_field", value: "Tag")
- Diese Zeile ist auskommentiert (
//). Sie würde das Feld (“_field”) umbenennen in “Tag”. Im aktuellen Zustand bleibt der Feldname unverändert.
5. Daten aggregieren
Code-Snippet|> aggregateWindow(every: 30d, fn: last, timeSrc: "_start", createEmpty: false)
aggregateWindow: Aggregiert die Daten in Fenstern.
every: 30d: Definiert die Fenstergröße auf 30 Tage.fn: last: Wählt für jedes Fenster den letzten Wert (“last”).timeSrc: "_start": Bezieht sich auf den Startzeitpunkt (“_start”) jedes Fensters.createEmpty: false: Stellt sicher, dass keine leeren Fenster (“empty”) erzeugt werden, falls in einem Monat keine Daten vorhanden sind.
6. Differenzierung (optional)
Code-Snippet|> difference()
- Diese Zeile ist optional und aktuell nicht aktiv.
difference() würde die aggregierten Werte vermutlich gegeneinander verrechnen. Ohne Kontext zur Datenstruktur ist die genaue Funktion hier unklar.
Zusammenfassung
Diese Abfrage filtert die Daten Ihres Home Assistant Systems, um den Gesamt-kWh-Verbrauch eines bestimmten Zählers zu erhalten. Anschließend werden die Daten in monatliche Werte aggregiert, wobei der letzte Wert jedes Monats verwendet wird. Die Berliner Zeitzone wird für die Interpretation der Zeitangaben berücksichtigt.