Leider habe ich ein paar Geräte, welche mindestens sekündlich Daten liefern, und das bei vielen Entitäten. Dazu zählt der SMA Wechselrichter und Batteriespeicher, sowie diverse Shellys.
Das führt dazu, dass meine Datenbankgröße relativ schnell ansteigt. Zudem wollte ich mich nicht mit 10 Tagen History zufriedengeben und bin auf 180 Tage hoch:
recorder:
purge_keep_days: 180
Das sorgte dafür, dass die DB schnell auf über 40Gb anstieg. Ich bemerkte das auch erst, weil die Backups ewig brauchten.
Also erstmal recorder filtering genutzt, was viel brachte, aber nicht meine 100%ige Zufriedenheit…
exclude:
domains:
# - device_tracker
- media_player
- uptime
- update
- time_date
- worldclock
- weather
- geo_location
entity_globs:
- sensor.*uptime*
- sensor.*voltage*
- sensor.*frequency*
- sensor.*_l1
- sensor.*_l2
- sensor.*_l3
- switch.*sync*
- switch.*reverse*
- switch.wled_*current*
- switch.wled_*count*
- switch.wled_*palette*
- light.wled*
- button.*update*
- button.*restart*
- sensor.hlk_ld2410b_a2e6*
entities:
- sensor.bsb_lan_status
- homematic.ccu2
Die DB war nun kleiner, wir reden aber noch immer von über 7Gb. Tendenz steigend.
Einer der nächsten Schritte war es nun auf MariaDB zu wechseln und mir danach InfluxDB genauer anzuschauen.
Maria DB für 180 Tage.
InfluxDB ohne Zeitbegrenzung → möchte ich, um auch nach Jahren noch Daten vergleichen zu können.
In InfluxDB hab ich dann weitere Retention Policies angelegt:
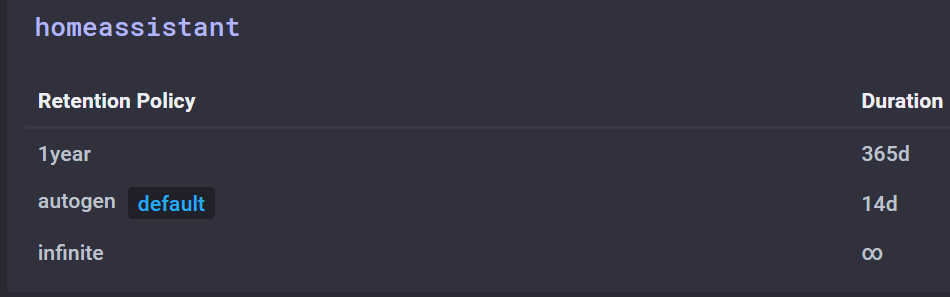
Die haben unterschiedliche Gültigkeitswerte für die jeweiligen Daten. InfluxDB kümmert sich von selbst um das löschen der alten Daten.
Nun müssen die Daten in die neuen Retention Policies eingefügt werden. Auch das geschiet automatisch über Continuos Querys:
CREATE CONTINUOUS QUERY cq_downsample_1h ON homeassistant BEGIN SELECT mean(*) INTO homeassistant.infinite.:MEASUREMENT FROM homeassistant.autogen./.*/ GROUP BY time(1h), * fill(previous) END
CREATE CONTINUOUS QUERY cq_downsample_5min ON homeassistant BEGIN SELECT mean(*) INTO homeassistant."1year".:MEASUREMENT FROM homeassistant.autogen./.*/ GROUP BY time(5m), * fill(previous) END
Man achte bei “Group by” auf den Zeitwert in “time”. Hier wird der durchschnittswert errechnet. Die Retention Policy “1year” hat 5 Minuten Durchschnittswerte und “infinite” Stunden Durchschnittswerte.
Somit habe ich 14 Tage alle Werte, Ein Jahr mit 5 Minuten Werten und unendlich mit Stunde.
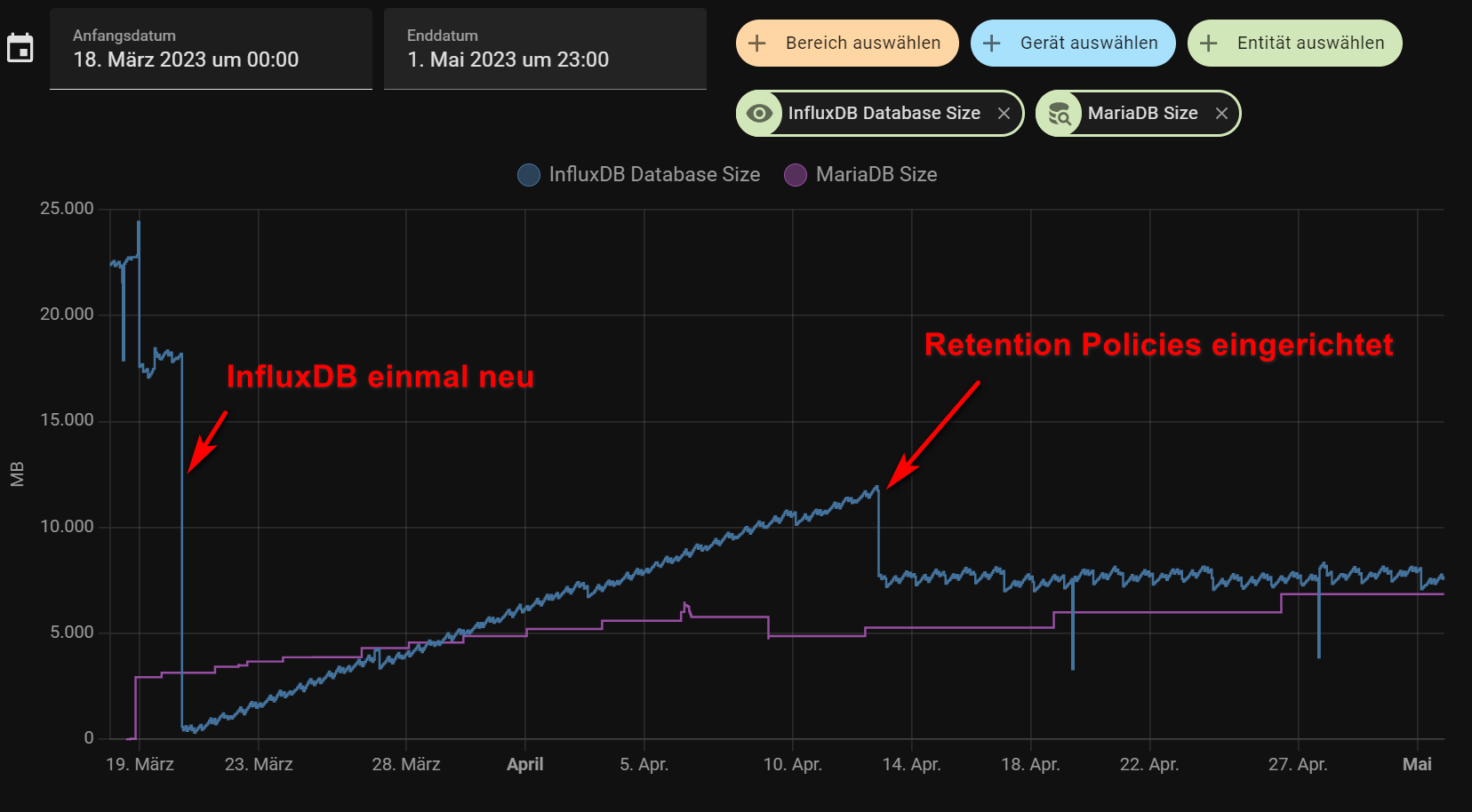
Man sieht schön, wie die Größe der InfluxDB ab dem 13. April nicht mehr steigt.
Somit sollte auch auf längere Zeit ein zurückgreifen auf Daten möglich sein, ohne das die Datenbank ins unermessliche wächst.
Es gibt bestimmt noch weitere coole Dinge die man mit InfluxDB machen kann. Da beschäftige ich mich dann erst demnächst irgendwann mit ![]()