Hallo zusammen,
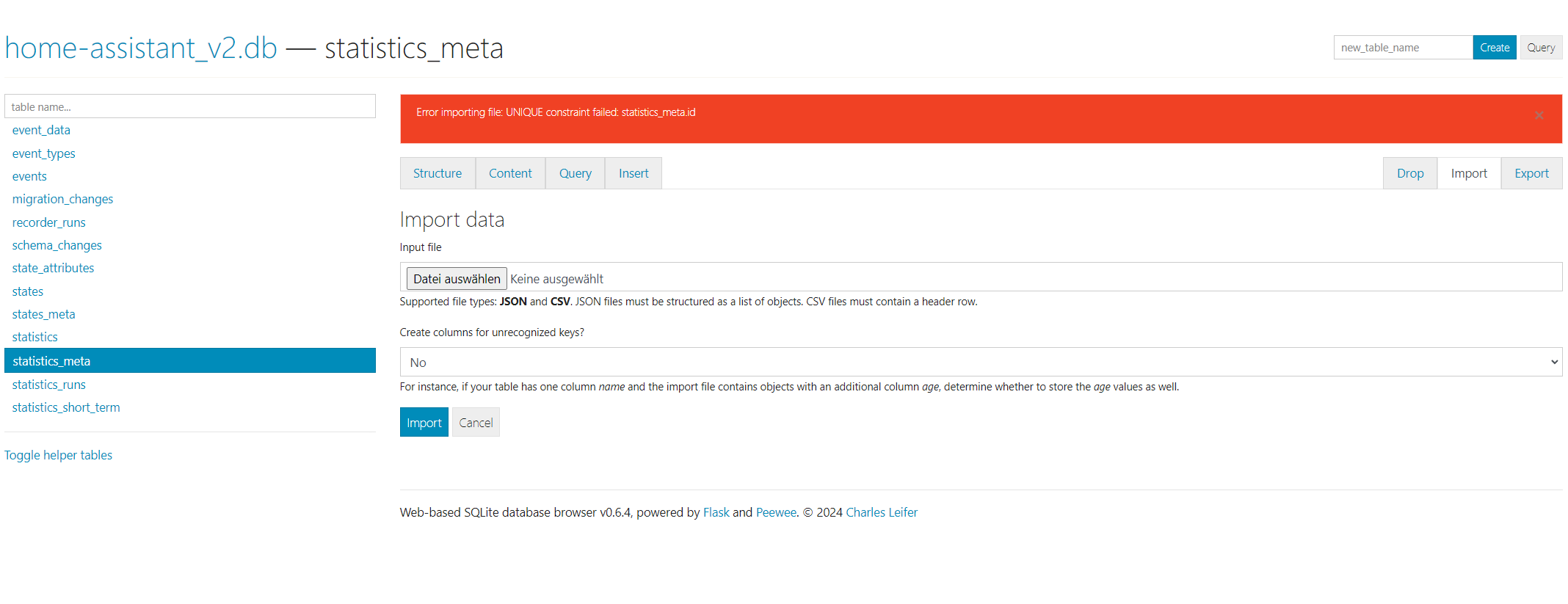
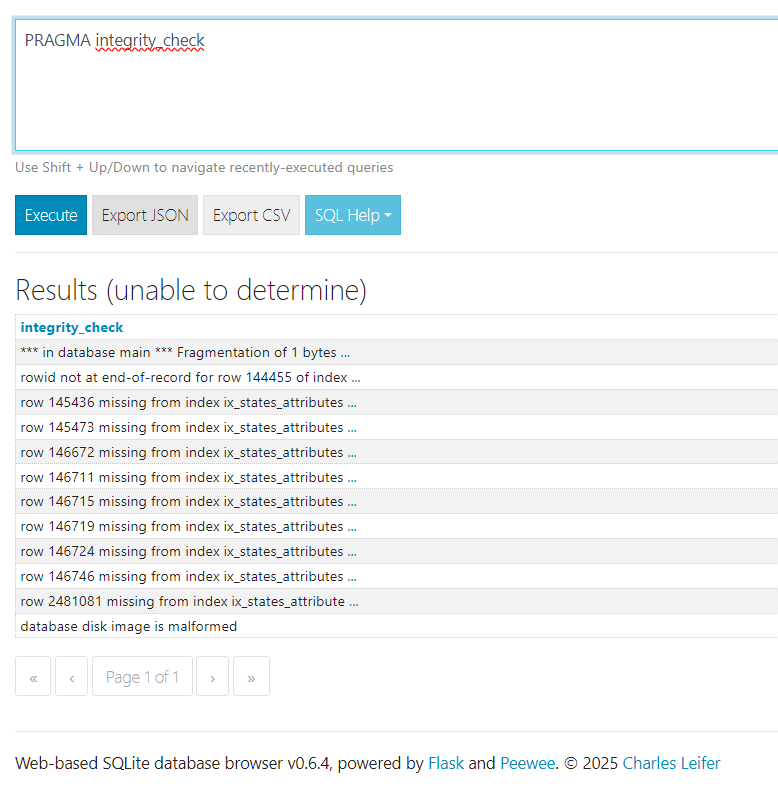
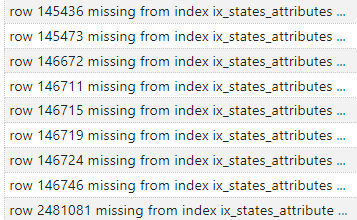
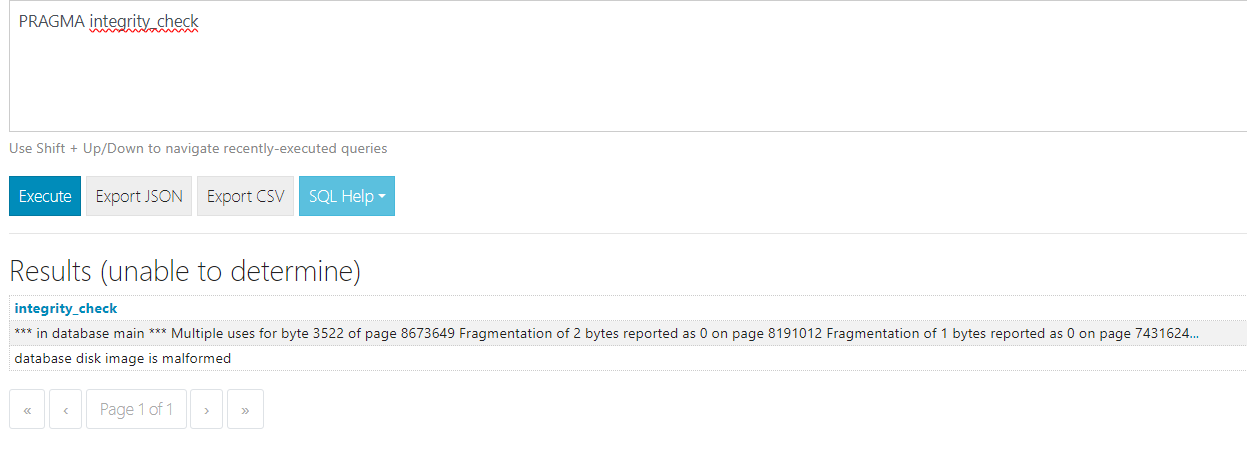
ich habe seit Monaten das Problem, dass meine Datenbank kaputt geht und dann neu anfangen will. Das “löse” ich dann temporär mit dem SQLite3 .repair mithilfe einer Datenbank aus dem Backup.
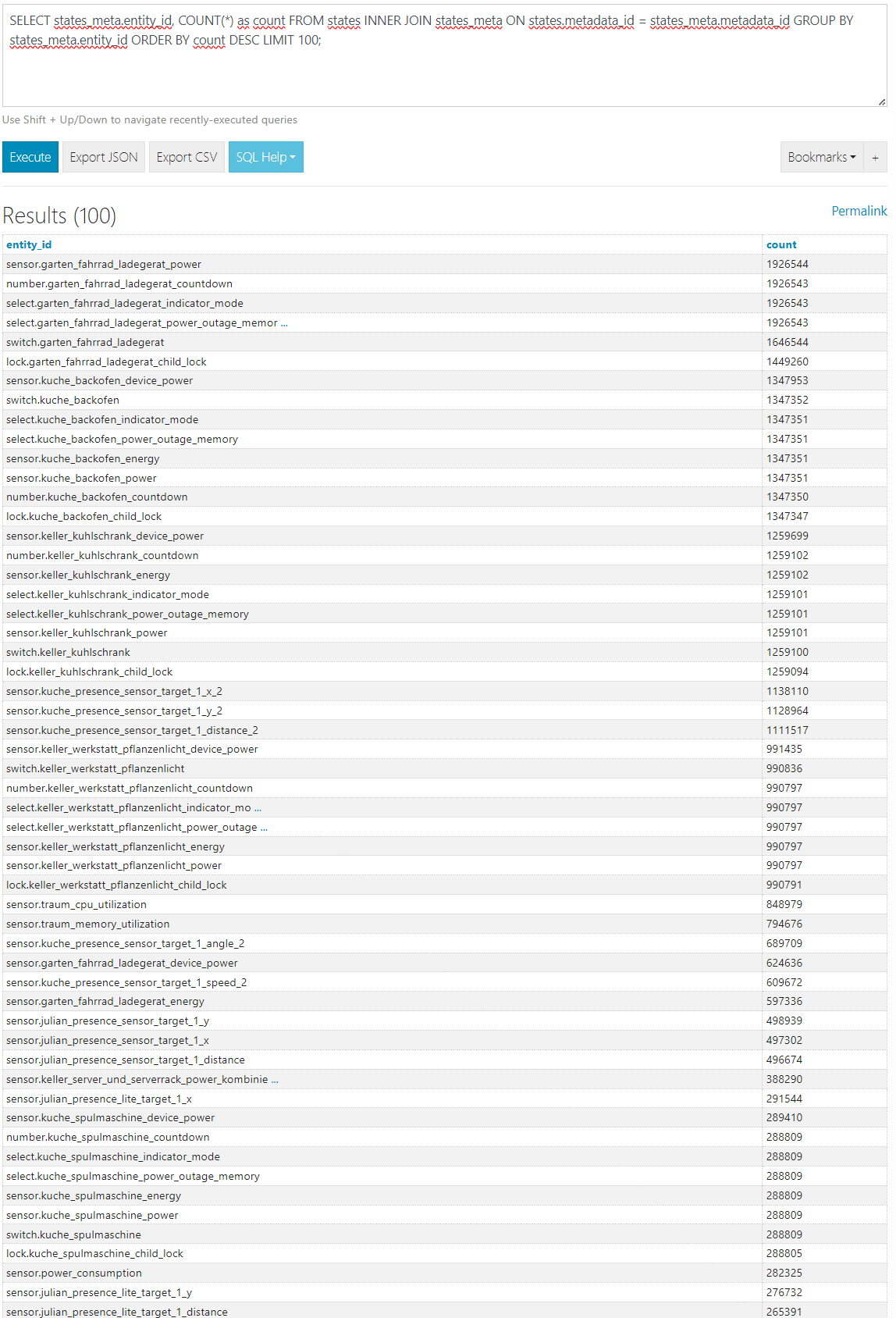
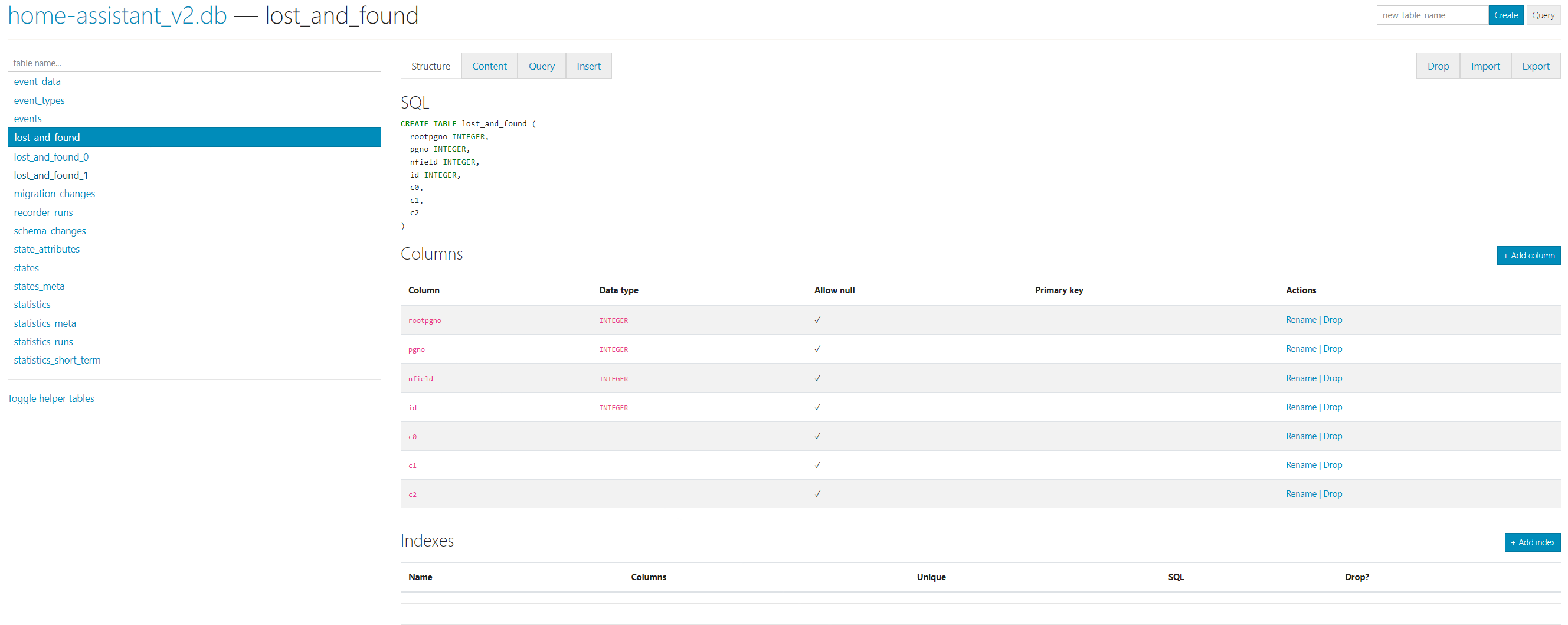
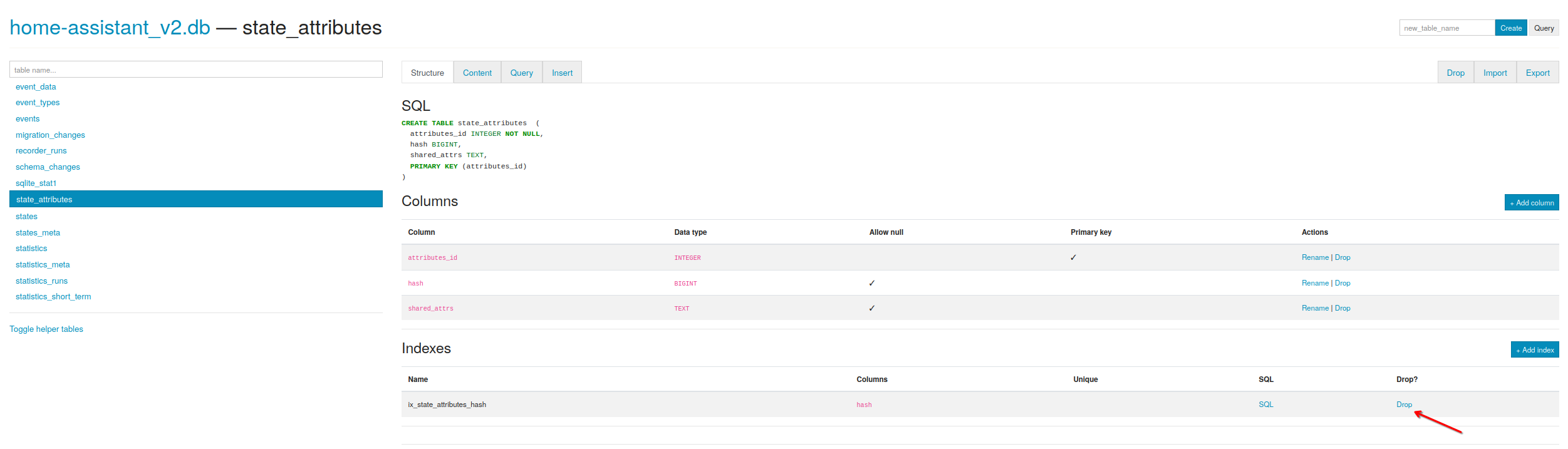
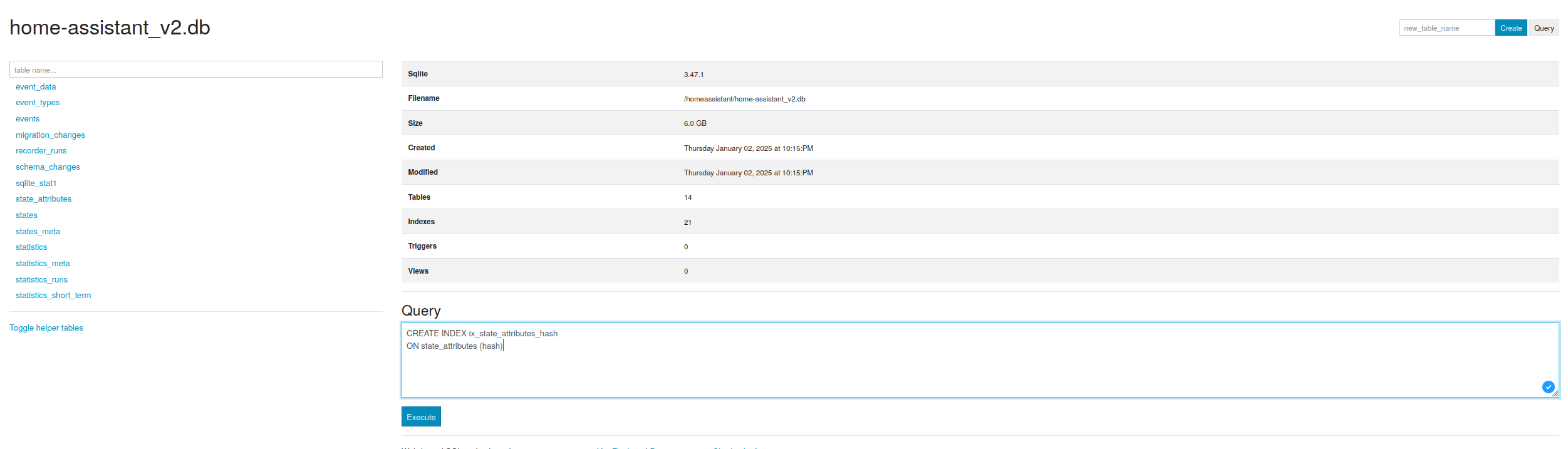
Inzwischen passiert es alle paar Tage und ich denke die Größe der Datenbank ist das Problem (aktuell 31 GB).
Daher habe ich mich an die recorder Einstellungen gemacht und einige Ausschlüsse definiert, unter Anderem auch nachdem ich mit den SQL Queries aus dieser Anleitung (How to keep your recorder database size under control - Community Guides - Home Assistant Community) meine, sinnvolle Ausschlüsse in meiner yaml definiert zu haben.
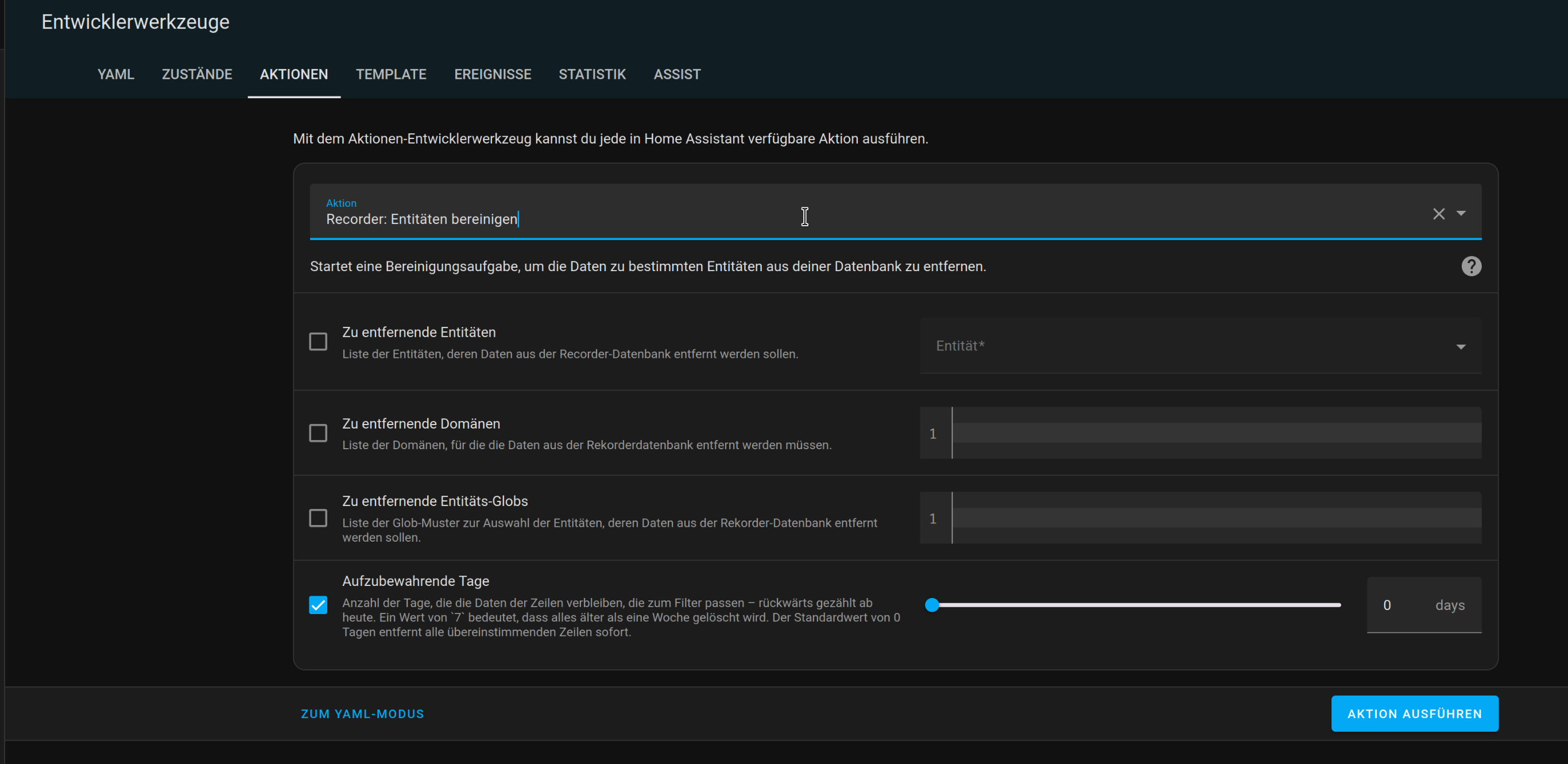
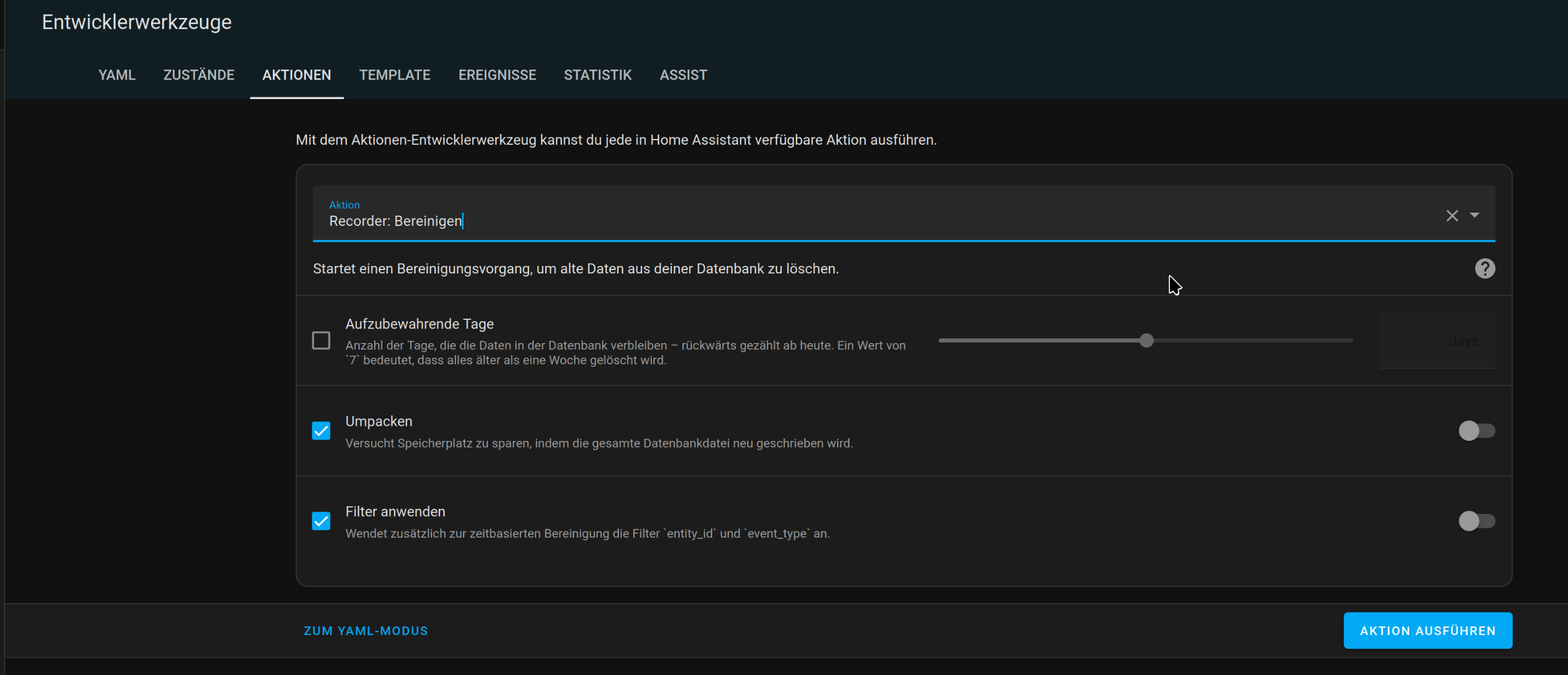
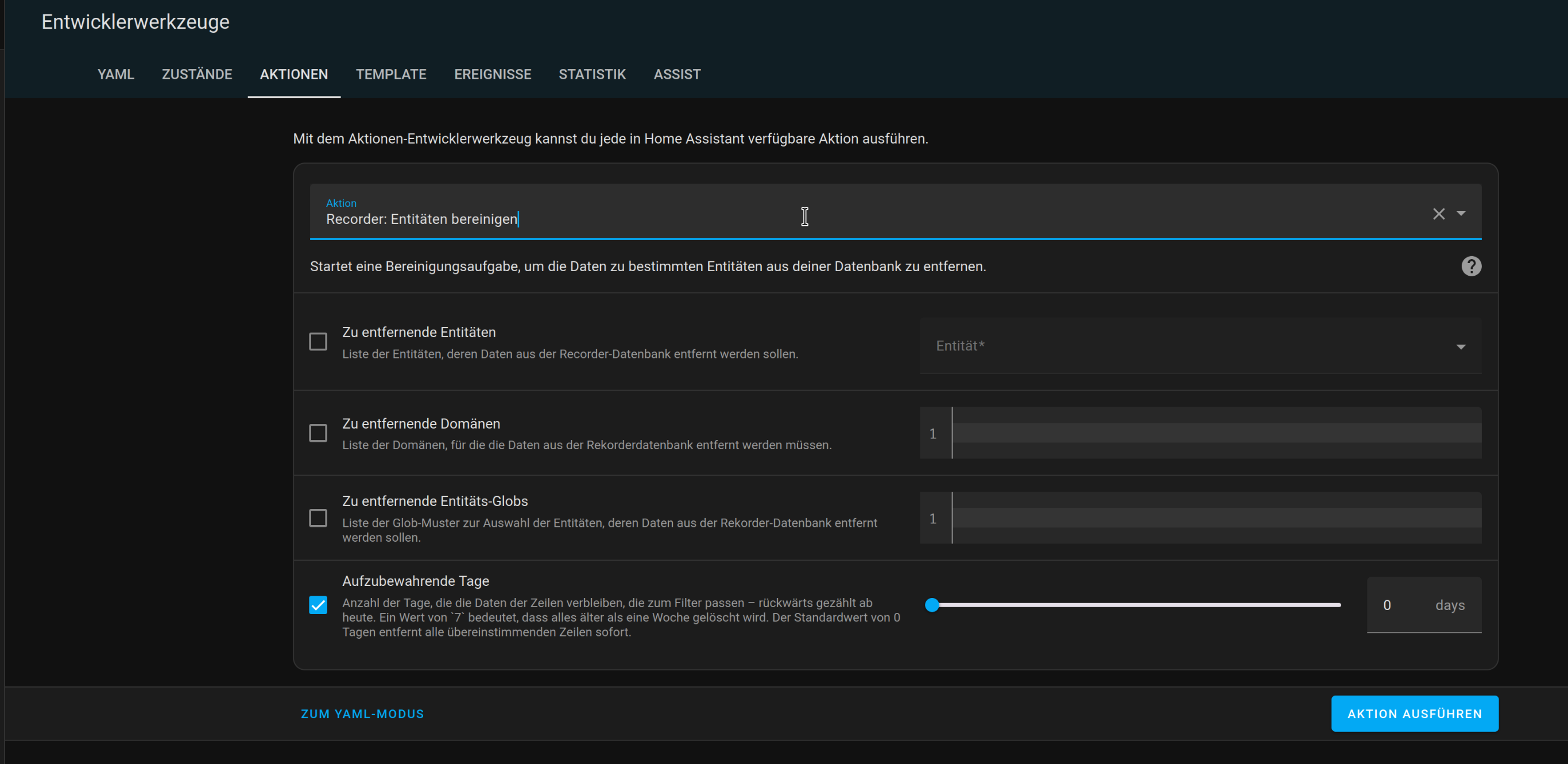
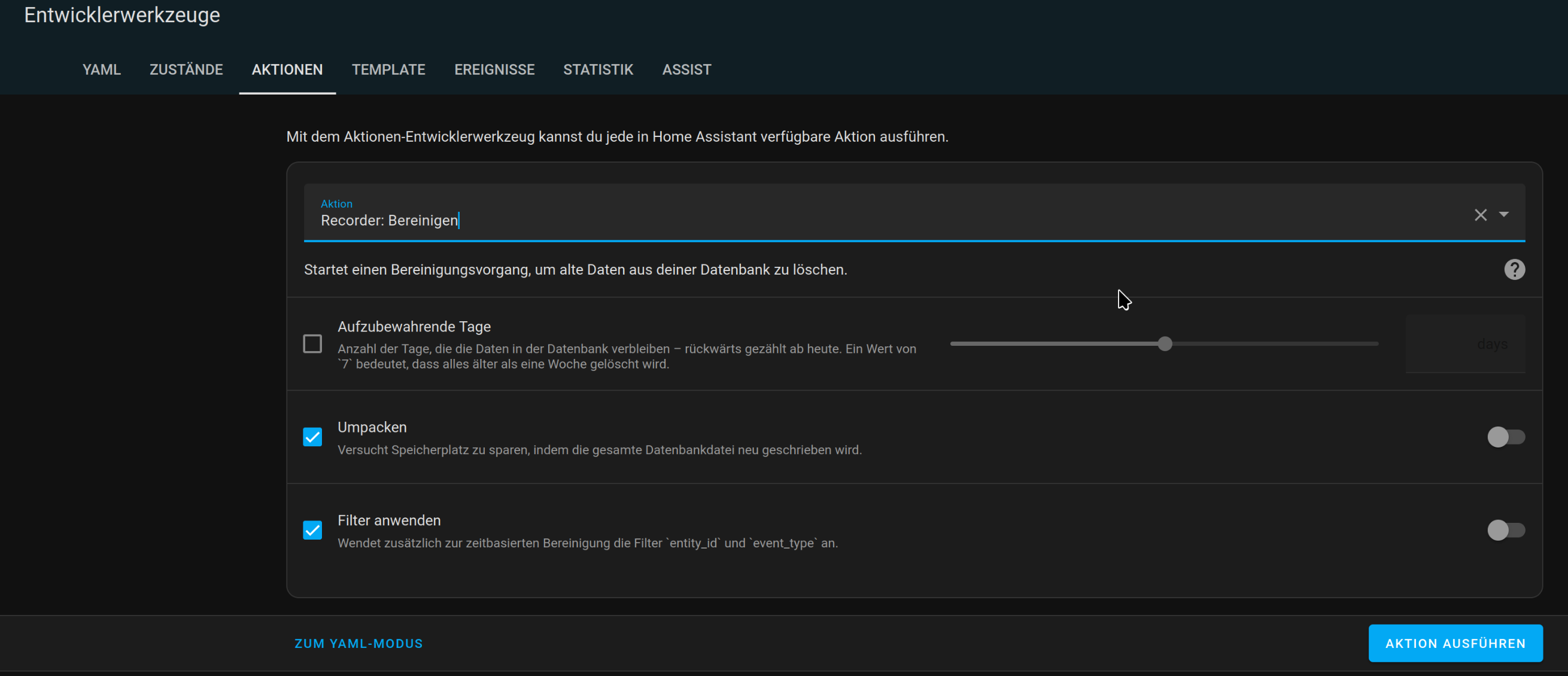
Wenn ich den purge mir repack durchführe, wird die Datenbank höchstens ein paar MB kleiner, nicht aber wie erhofft sehr viel kleiner.
Ziel ist grundsätzlich, alles nach einigen Tagen zu verwerfen, das nicht für das Energy Dashboard wichtig ist (was die energy Werte der Einzelgeräte einschließt).
Hier meine yaml (der recorder Teil)
recorder:
purge_keep_days: 30 # Standard-Aufbewahrungszeit für weniger wichtige Daten: 30 Tage
auto_purge: true # Automatische Bereinigung aktivieren
# commit_interval: 1 # Daten werden häufiger geschrieben, um Stabilität zu erhöhen
include:
entities: # Wichtige Entitäten für Langzeitaufbewahrung
# Gesamtstromverbrauch
- sensor.energy_consumption_sum
# Grid Consumption und Kosten
- sensor.energy_import_daily
- sensor.energy_import_daily_cost
- sensor.energy_import_sum
# Grid Return
- sensor.energy_export_monthly
- sensor.energy_export_sum
# Solar Production
- sensor.pv_schuppen_lifetime_production
- sensor.pv_donato_lifetime_production
# Wasserverbrauch und Kosten
- sensor.watermeter_value
# - sensor.watermeter_value_cost
# Geräte-Verbrauch
- sensor.garten_fahrrad_ladegerat_energy
- sensor.waschmaschine_energy
- sensor.keller_trockner_energy
- sensor.kuche_kuhlschrank_energy
- sensor.kuche_wassersprudler_energy
- sensor.keller_technikraum_julian_pc_energy
- sensor.kuche_kaffeemaschine_energy
- sensor.keller_technikraum_server_energy
- sensor.keller_kuhlschrank_energy
- sensor.julian_stecker_klimagerat_energy
- sensor.warmepumpe_stromverbrauch_ohne_cee
- sensor.kuche_spulmaschine_energy
- sensor.kuche_backofen_energy
# - sensor.rack_stromverbrauch_ohne_pc # aktuell ohne server
# - sensor.julian_kogeek_schreibtisch
- sensor.wohnzimmer_media_energy
- sensor.all_lichter_energy
- sensor.shelly_pro_3em_cee_dose_total_active_energy
- sensor.keller_werkstatt_pflanzenlicht_energy
- sensor.keller_pflanzenlicht_alle_energy
# general include
- sensor.solar_total
# - sensor.shelly_pro_3_em_warmepupe_total_active_power
exclude:
event_types:
- call_service # ausgeschlossen weil viele Daten
- automation_triggered # ausgeschlossen weil viele Daten
- service_registered # ausgeschlossen weil viele Daten
- entity_registry_updated # ausgeschlossen weil viele Daten
domains: # Ausschließen unwichtiger Domains
- script
- logbook
- mobile_app
- updater
- media_player
- persistent_notification
entities: # Ausschließen von spezifischen Entitäten
- sensor.switch_device_power
- sensor.watermeter_rate_per_digitalization_round
# Voltage
- sensor.shellypro3em_0cb815fd745c_phase_b_voltage
- sensor.shellypro3em_0cb815fd745c_phase_c_voltage
- sensor.shelly_pro_3_em_warmepupe_phase_a_voltage
- sensor.shelly_pro_3_em_warmepupe_phase_b_voltage
- sensor.shelly_pro_3_em_warmepupe_phase_c_voltage
- sensor.shelly_pro_3em_cee_dose_phase_a_voltage
- sensor.shelly_pro_3em_cee_dose_phase_b_voltage
- sensor.shelly_pro_3em_cee_dose_phase_c_voltage
# Current
- sensor.shellypro3em_0cb815fd745c_phase_c_current
- sensor.shelly_pro_3_em_warmepupe_phase_a_current
- sensor.shelly_pro_3_em_warmepupe_phase_b_current
- sensor.shelly_pro_3_em_warmepupe_phase_c_current
- sensor.shelly_pro_3em_cee_dose_phase_a_current
- sensor.shelly_pro_3em_cee_dose_phase_b_current
- sensor.shelly_pro_3em_cee_dose_phase_c_current
# Frequency
- sensor.shellypro3em_0cb815fd745c_phase_c_frequency
- sensor.shelly_pro_3_em_warmepupe_phase_a_frequency
- sensor.shelly_pro_3_em_warmepupe_phase_b_frequency
- sensor.shelly_pro_3_em_warmepupe_phase_c_frequency
- sensor.shelly_pro_3em_cee_dose_phase_a_frequency
- sensor.shelly_pro_3em_cee_dose_phase_b_frequency
- sensor.shelly_pro_3em_cee_dose_phase_c_frequency
# Apparent Power
- sensor.shellypro3em_0cb815fd745c_phase_c_apparent_power
- sensor.shelly_pro_3_em_warmepupe_phase_a_apparent_power
- sensor.shelly_pro_3_em_warmepupe_phase_b_apparent_power
- sensor.shelly_pro_3_em_warmepupe_phase_c_apparent_power
- sensor.shelly_pro_3em_cee_dose_phase_a_apparent_power
- sensor.shelly_pro_3em_cee_dose_phase_b_apparent_power
- sensor.shelly_pro_3em_cee_dose_phase_c_apparent_power
# Power Factor
- sensor.shelly_pro_3_em_warmepupe_phase_a_power_factor
- sensor.shelly_pro_3_em_warmepupe_phase_b_power_factor
- sensor.shelly_pro_3_em_warmepupe_phase_c_power_factor
- sensor.shelly_pro_3em_cee_dose_phase_a_power_factor
- sensor.shelly_pro_3em_cee_dose_phase_b_power_factor
- sensor.shelly_pro_3em_cee_dose_phase_c_power_factor
# Device Temperature
- sensor.shelly1pm_ba5328_device_temperature
- sensor.shellypro3em_0cb815fd745c_temperature
- sensor.shelly_pro_3_em_warmepupe_temperature
- sensor.shelly_pro_3em_cee_dose_temperature
entity_globs:
- sensor.006_*
- switch.006_*
- binary_sensor.006_*
- number.006_*
- cover.006.*
- select.006_*
Ist die YAML inkorrekt definiert? Mache ich beim Purge was falsch? Was mache ich falsch?
Danke schon mal!