Da gebe ich dir Recht, es macht kein Sinn einen unveränderten Zustand immer wieder in die Datenbank zu schreiben.
Ich habe mir mal erlaubt in meine MariaDB und in die InfluxDB zu schauen was da gespeichert wird. Hierbei habe ich ein Fensterkontakt gesucht und gefunden :-)
Also, die MariaDB hat jede Menge Einträge bei dem der Zustand unverändert ist (Ich öffne meine Fenster in der Regel nicht). Interessant ist auch der Zeitstempel in "last_updated". Ich kann keine Regelmäßigkeit erkennen.
Ich behaupte einfach mal, dass nach jedem Neustart alle Daten einmal in die DB geschrieben werden. Sprich, man "müllt" sich die DB zu wenn man neu startet.
Bei der InfluxDB sieht es genau so aus.
Also eine sehr schöne Lösung und es werden nicht die ganze Zeit unnötig Daten in die DBs geschrieben 👍
@tower Das nach jedem Neustart alle Messwerte einmal erfasst werden ist doch logisch. HA wird ja nicht beim Runterfahren speichern wieviel Zeit von welchem Intervall an welcher Entität noch übrig war. Neustart heißt immer alles, was in einem Intervall erfasst wird, startet wieder neu. Das wird man nicht verhindern können.
Man kann aber auch schön aus deinen Daten erkennen das HA wenn er nicht neu gestartet wird, bei einem Fensterkontakt nur ein bis zwei Einträge pro Tag macht.
Tatsächlich gibt es auch Tage an denen gar nichts gespeichert wird, so lange man nicht neu startet. Beispiel in dem Screenshot von der InfluxDB, da sind keine Einträge für die Tage 09.01-11.01.
Ich habe von iobroker auf ha migriert. im iobroker hatte ich eine mysql datenbank (inhalt ca 10 Jahre) und 5 Jahre in Grafana (parallel oder waren es auch 10?). Aus IT technischer Sicht (hier kommt wieder es business) macht die influxdb am meisten sinn. eine mysql datenbank ist eher sinnlos.
Ich kann euch nur zu Grafana und der influxdb raten. ich hab hier alleine sicherlich schon 2000h für dashboards (verbraten). es macht spass, es gibt 1000 videso (how to) und die einbindung von HA in die influxdb ist easy.
schnell eine maschine via proxmox, docker (portainer, kubernetes) und los geht der spass. langweillig wird einem nie und grafisch kann man sich austoben.
es isch nicht rocket science - das kann jeder und macht auch jeder.
Nutzt du die Oberfläche von HA dann gar nicht mehr, oder nutzt du Grafana in der GUI von HA?
Da du ja echt viel Erfahrung hast würde ich dich darum bitte mal ein paar Bausteine oder vielleicht sogar ganze Dashboards mit uns zu teilen... (Vielleicht im passenden Bereich in diesem Forum)
Habe mit Grafana eher wenig Erfahrung und habe gerade Angst, dass du mich dazu motivieren wirst Grafana intensiver zu nutzen (noch eine Baustelle mehr...) 😫
ich nehme auch an dass es ein Docker Container ist. Aber die Daten von MariaDB werden ja wahrscheinlich reingemountet sein. Also außerhalb vom Container liegen.
Ich kann bei meinem EnergieDashboard die einzelnen Tage bis zum Begin der Aufzeichnung zurückgehen. Das ist bei mir ca. 10 Monate.
Ihr geht mit euren Gedanken schon in die richtige Richtung.
MariaDB ist eine relationale Datenbank. Ralationale Datenbanken eignen sich durch ihren tabellarischen Aufbau sehr gut, einen aktuellen Status zu speichern, aber weniger, um deren Verlauf über die Zeit zu speichern. Das Sensor-Daten über längere Zeiträume dort gespeichert werden, ist zwar möglich, aber suboptimal. Eine MariaDB von mehreren GB Größe performant zu betreiben, und vor allem abzufragen, ist schon sportlich.
Da kommt influxDB ins Spiel. Das ist eine Timeseries-Datenbank, die genau dafür gedacht ist: Mit Zeitstempel versehene Daten zu speichern; in großen Mengen, und über einen langen Zeitraum.
Was HA angeht, ergänzen sich beide Datenbanken also sehr gut, sie ersetzen sich aber nicht.
Lest Euch das hier mal durch, das erklärt die Zusammenhänge in HA sehr gut (ist aber leider in englisch).
Während die Installation relativ einfach ist, sowohl für MariaDB als auch für influxDB, wird es dafür umso schwieriger, die Daten zur richtigen DB zu schicken.
Mit includes und excludes könnt ihr aber sehr genau bestimmen, welche Daten wohin sollen. Ihr müsst noch nichtmal Sensoren in MariaDB excluden, nur solltet ihr euch von zwei- oder gar mehrstelligen GB Größen verabschieden. entsprechend kurz sollte die Aufbewahrungsdauer gesetzt werden.
Einen Nachteil gibt es aber: Die Daten aus influxDB können nicht ohne weiteres in Lovelace dargestellt werden, dazu muss man den Umweg über Grafana gehen - wobei Grafana viel mehr kann als es jede Card kann…
Ende April kommt übrigens mein Video zu Grafana & InfluxDB. Das ist so umfangreich geworden, so mancher hätte daraus einen Bezahl-Kurs auf Udemy gemacht. Ich würde mich dann sehr über euer Feedback freuen
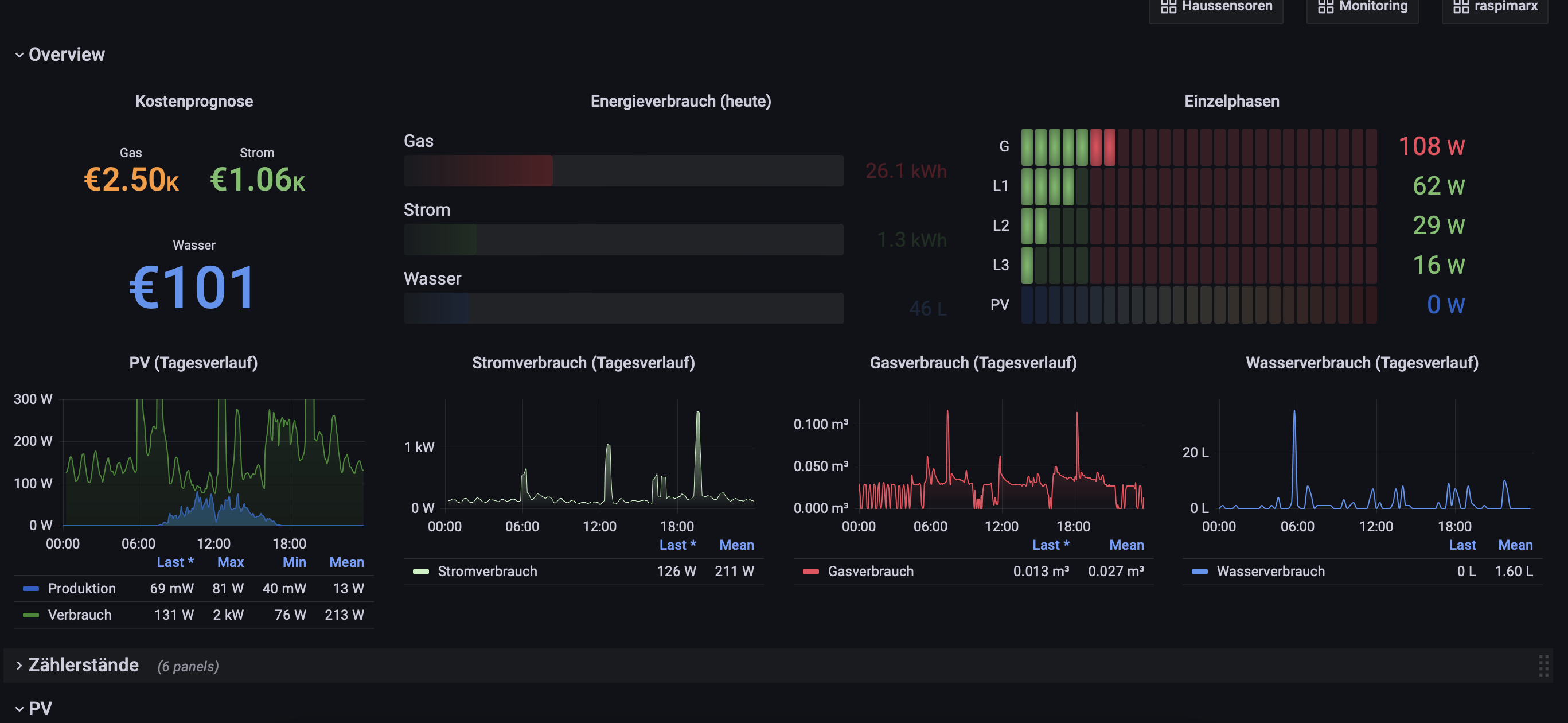
Mein Weg hinsichtlich Langzeitspeicherung geht alleinig über InfluxDB. Dort laufen insbesondere alle Verbrauchs-/Erzeugungsdaten (Gas, Wasser, Strom, PV) rein. Die Energiedaten können dann über Grafana sehr schön und übersichtlich dargestellt werden. HA nutze ich primär für die Automatisierungen und als zweites System zur Erfassung der Verbrauchsdaten. Hier aber dann in der Standard sqllite Datenbank. Alles läuft in Docker und das seit ca. 2 Jahren stabil.
Bei den einzelnen Buckets der InfluxDB habe ich dann noch unterschiedliche s.g. “Retention-Policies” definiert. So wird bei mir was Verbrauchsdaten angeht alles für immer gespeichert. Temperaturdaten speicher ich für 12 Monate und das Monitoring meiner Container und Skripte speicher ich nur für 7 Tage.
Mittlerweile ist mein Grafana-Dashboard recht umfangreich geworden. Das ist aber auch eher nebensächlich. Hauptsache es liegt erstmal alles in der InfluxDB
Die MariaDB speichert ihre Daten für immer, es seidenn dies wird in der Configuration.yaml runter gesetzt.
Das Logbuch speichert die Daten allesdings nur für zirka 10 Tage.
In der InfluxDB kann man das beim erstellen der Verbindung zu HA einstellen.
Vor einige Wochen gab es ein größeres Update für die MariaDB und HA.
Ich glaube man musste auf die Reihenfolge beim Updaten achten, was ich nicht gemacht habe.
Dadurch lief nichts mehr stabil und ich habe mich dazu entschieden von vorne zu starten und das Ganze auch vom Pi auf NUC umzuziehen.
Jetzt ist meine DB wieder relativ groß (<2GB) und ich möchte jetzt intensiver mit “include” & “exclude” arbeiten.
Habe mal ein paar “domains” zu exclude hinzugefügt und es hat auf anhieb funktioniert.
Aber wie bekomme ich es jetzt hin, dass die schon gespeicherten Entitäten, die ich jetzt mit “exclude” nicht mehr haben möchte aus der DB bekomme?
Nach Möglichkeit nicht manuell aus der DB löschen.
Ich vermute, dass ich mit “recorder.purge” arbeiten müsste. Aber damit habe ich keine Erfahrung.
Hat jemand mit diesem Vorhaben Erfahrungen die Er/Sie mit mir teilen könnte?
Möchte auf keinen Fall zu viel löschen!
@PhUser
Sowohl im Verlauf als auch im Logbuch sind nur die Daten aus der recorder-Datenbank verfügbar, i.d.R. MySQL oder MariaDB. Und es sind genau die Daten aus dem Verlauf, die HA direkt benutzt, aber auch von Cards als z.B. Grafiken dargestellt werden.
Die Daten aus der influxDB stehen somit also nur über den Umweg Grafana zur Verfügung.
Da kann ich leider nichts zu beitragen. Ich nutze InfluxDB quasi als standalone Lösung und ziehe mir die benötigten Daten per Grafana aus den einzelnen Buckets. Meine HA Installation schiebt die Daten in die Standard-sqllite Datenbank.